语料库相关
2018EMNLP:MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling
这篇是2018EMNLP最佳论文之一。
这篇文章构建了一个Multi-Domain Wizard-of-Oz数据集。
特点:
- 数据内容是有关旅游业服务的,包含7个领域包括:医疗、警察、宾馆、餐厅、出租车、火车、吸引力等
- 数据量大。共有10438个对话,70%的对话超过10轮。比目前的数据集大一个数量级。与现有数据集相比,句子的长度更长,回复更多样。
- 3406个单一领域的对话,7032个涉及多领域的对话(2-5个领域)
- 数据结构包括:目标、多个用户和系统的语句、信念状态、每轮带有slot的一系列对话
用途:作为一种新的benchmark:
- dialogue state tracking
- dialogue management and response generation
- Natural Language Generation from a structured meaning representation
端到端的对话
2018EMNLP:Learning End-to-End Goal-Oriented Dialog with Multiple Answers
引入外部知识相关
2018 AAAI:Augmenting End-to-End Dialogue Systems with Commonsense Knowledge
这篇文章的观点是,由于外部知识数量巨大,所以更适合使用外部存储模块,而不是传统的在模型中通过参数进行编码。
它用来进行实验的问题限定在非任务导向领域,检索式方法的对话系统。
关于常识的检索:
我们假设常识库是由一系列关于概念C的断言A构成。每一条断言 可以表示为 表示c1和c2之间的关系。同时建立一个关于A的字典H。每一个概念c作为key,与c有关的a作为value。目的是可以检索到一条信息中涉及概念的全部常识。为与c相关的全部断言的集合。

网络模型
将常识融入进对话模型的方法是用另一个额外的LSTM对论断a进行编码
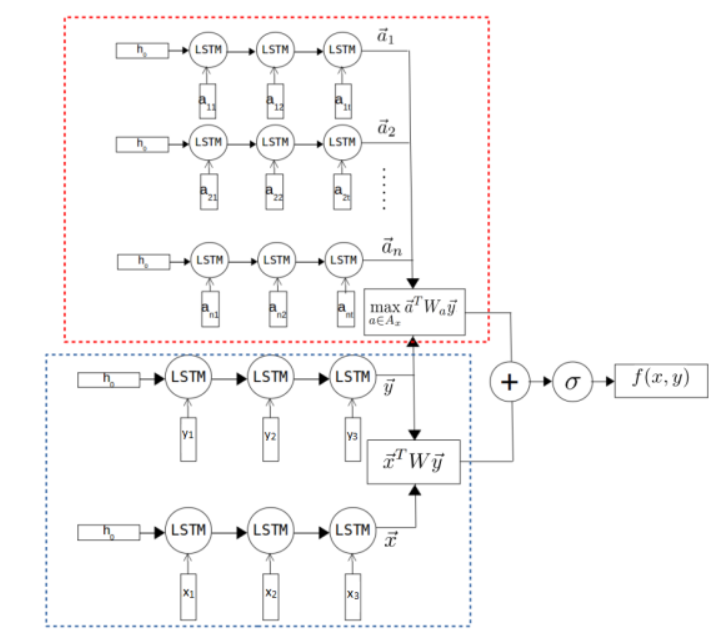
上半部分是常识论断的编码网络,下半部分是一个Dual-LSTM网络,用于回复的编码。原来a的形式是 ,由于c可能是一个多词组的概念,所以a就被转化为了token序列
对于R我们将其加入词汇表V中,将r看待为一个常规的单词来编码。同时我们决定不把每一个c都作为编码单元,因为数量太多。使用LSTM将a编码为embedding层的表示 。这个方法对于自然表达中良好的结构化断言都适用。
将断言a与回复y的匹配得分定义为:
在训练中被学习。
对于断言集
,大部分
总的Tri-LSTM编码模型可以被定义为
2018 ACL Knowledge Diffusion for Neural Dialogue Generation
该论文提出了一种 neural knowl-edge diffusion (NKD)网络来将知识引入对话生成,不仅可以进行对输入的表述进行事实匹配,还能将事实进行扩展,融合到相似的实体中。
概要
文中提到了知识库的应用之一是问答,常见的事实表示形式是一种三元关系(主题,关系,客体)。这在对话中同样重要,但是还不够,对话中常出现一种实体转移现象,如:
1 | A: Is there anything like the [Titanic]? |
涉及到的实体从《泰坦尼克号》扩展到了《魂断蓝桥》。NKD模型就可以表示这种实体的转移和扩展。
NKD模型
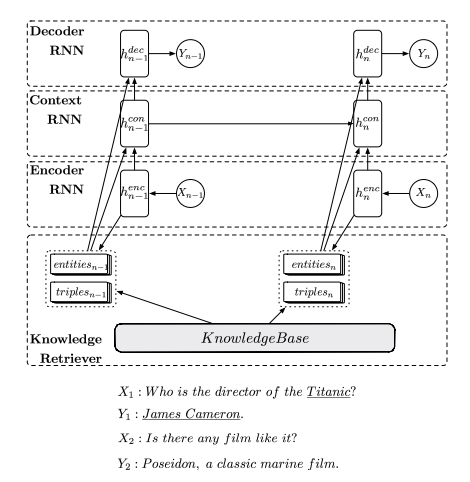
输入:
输出:
知识库K中的事实是以三元关系(主体、关系、客体)保存的。
由上图可以看到,模型主要有以下几个部分组成:
Encoder
将离散的tokens转化为向量表示。特别之处在于,为了捕捉不同方面的信息,利用两个独立的RNN产生两种隐状态序列:。我们利用最终的隐状态,输入上下文RNN来追踪对话状态。另一个用于知识检索,并用来为输入表述中的知识实体和关系进行编码。
Knowledge Retriever
知识检索通过从知识库中提取一系列事实并明确它们的重要性,可以让以知识为基础的对话系统既具有收敛性,同时在思考能力上又具有扩展性。对于思考能力的扩展主要依靠:事实匹配和实体扩展,如下图: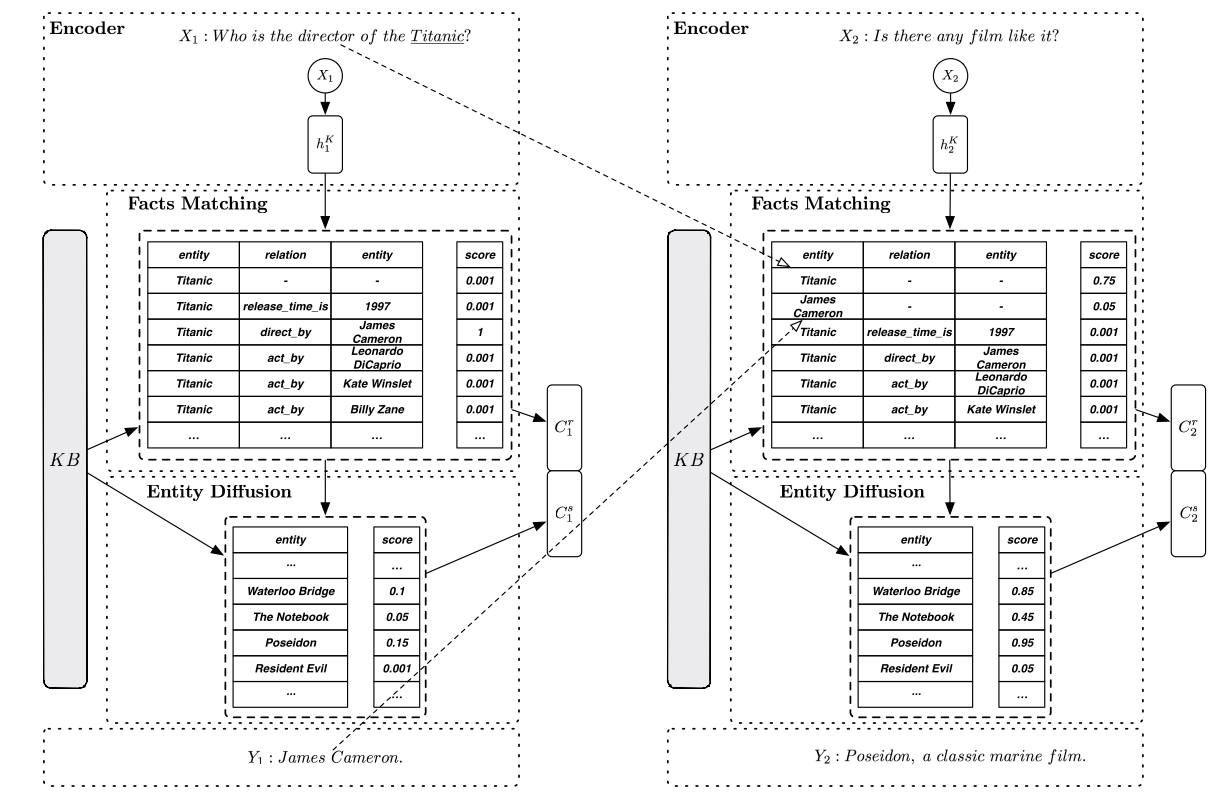
- 事实匹配
首先输入表述X和提取的隐状态,从知识库和历史对话中提取相关的事实。预先定义的事实数量的事实 通过字符串匹配、实体连接、命名实体识别来获得。如上图所示,第一句话“Titanic”被认为是一个实体,所有相关的三元知识结构都被提取出来。接着通过entity embedding和relation embedding将实体和这些知识被转化为事实表示 。事实和输入之间的关系系数范围是[0,1],通过非线性函数或者子神经网络计算。比如可以用一个多层感知机MLP:
对于多轮对话,之前表述中的实体也会被继承和保留,就像上图中的点连线所示。通过对的加权平均,一系列事实总结为相关事实表示
- 实体扩展
通过多层感知器计算知识库中实体(除了在前面出现的内容)与相关事实表示之间的相似性,得到相似系数re
是entity embedding。选出top 个实体作为相似实体。相似实体的表示定义为:
如上图,第一轮对话通过事实匹配得到最相关的事实是(Titanic,direct_by,JamesCameron)。当事实匹配完成,如果相关性很高,直觉上就不需要再进行实体扩展。而且进行实体扩展后发现相似度也不高。
但在第二轮对话,没有对应输入的知识,但是之前继承过来的实体“Titanic”得分较高,我们就对”Titanic”进行实体扩展,得到相似的实体”Waterloo Bridge”和“Posedion”。同时可以看到这两个实体的相似度得分在第二轮比第一轮要高。说明比第一轮的对话更合适。
Context RNN
记录了话语(utterance)层面的对话状态。它包括utterance representation和knowledge representation.隐状态在这一层被更新为:
被转移到解码器来引导回答生成
Decoder
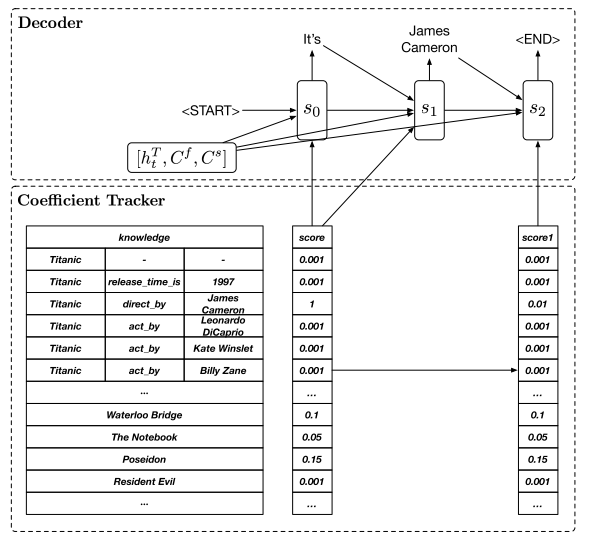
主要介绍了Vanilla decoder和Probabilistic gated decoder
数据集
作者爬取了百度知道和豆瓣电影的数据和讨论作为数据集。