前言
一直对nlp比较感兴趣,最近开始学习Stanford大学cs224d课程,对深度学习在nlp上的应用进行一些了解。之后每节课上完都会根据课程内容和一些其他人的博客在博客理笔记。第一节课绪论的内容非常简单,就不写了。从第二节课word2vec开始写起。
计算机中如何表示一个词的意思
word vector是一种在计算机中表达word meaning的方式。在Webster词典中,关于meaning有三种定义:
- the idea that is represented by a word, phrase, etc.
- the idea that a person wants to express by using words, signs, etc.
- the idea that is expressed in a word of writing, art, etc.
计算语言学中常见的表示词义的方式是WordNet那样的词库。包含有上位词(is-a)关系和同义词集.比如NLTK中可以通过WordNet查询熊猫的hypernyms (is-a,上位词),得到“食肉动物”“动物”之类的上位词。也可以查询“good”的同义词——“just品格好”“ripe熟了”。
这种表示方式叫做discrete representation
discrete representation && one-hot vector
它有许多缺点:
- 缺少新词
- 主观化
- 需要耗费大量人力去整理
- 无法准确计算词之间的相似度
传统的基于规则或基于统计的自然语义处理方法将单词看作一个原子符号:hotel, conference, walk。在向量空间的范畴里,这是一个1很多0的向量表示:[0,0,0,0,…,0,1,0,…,0,0,0]。
这种表示方法存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系。比如Dell notebook battery size和Dell laptop battery capacity。而one-hot向量是正交的,无法通过任何运算得到相似度。
Distributional similarity based representations
现代nlp一个很成功的思想是:将单词放到上下文中去理解它的含义。
You shall know a word by the company it keeps

通过向量表示词语含义
通过调整一个单词及其上下文单词的向量,使得根据两个向量可以推测两个词语的相似度;或根据向量可以预测词语的上下文。这种手法也是递归的,根据向量来调整向量,与词典中意项的定义相似。
另外,distributed representations与symbolic representations(localist representation、one-hot representation)相对;discrete representation则与后者及denotation的意思相似。切不可搞混distributed和discrete这两个单词。
学习神经网络word embedding的基本思路
定义一个预测某个单词上下文的模型:
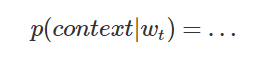
损失函数定义如下:
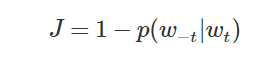
这里的表示的上下文(负号通常表示除了某某之外),如果完美预测,损失函数为零。
然后在一个大型语料库中的不同位置得到训练实例,调整词向量,最小化损失函数。
word2vec细节
根据最大似然估计,目标函数定义为所有位置的预测结果的乘积:
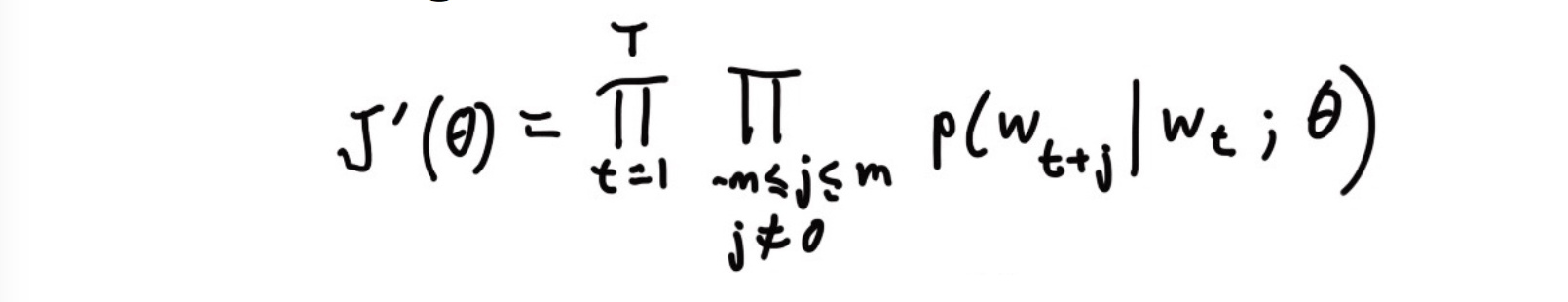
取对数便于优化,加负号将最小化变为最大化(习惯而已)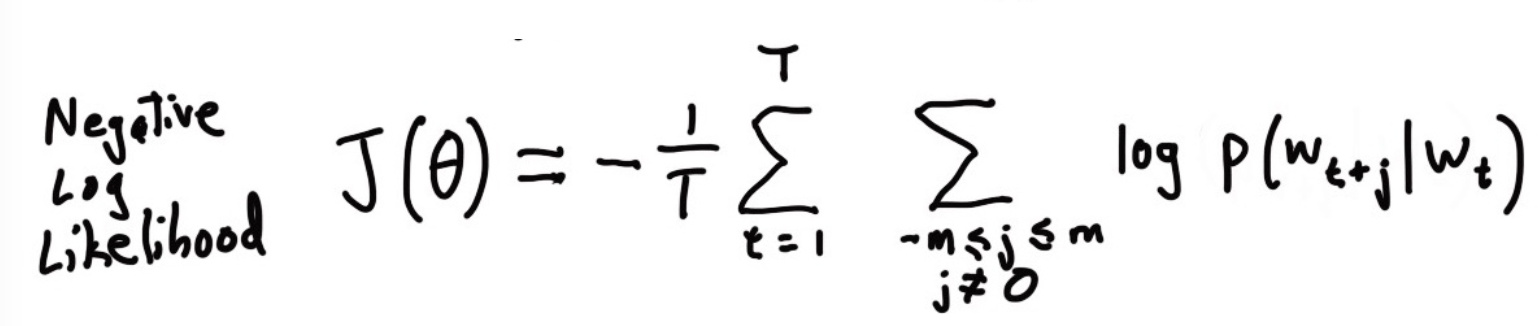
预测到的某个上下文条件概率可由softmax得到:
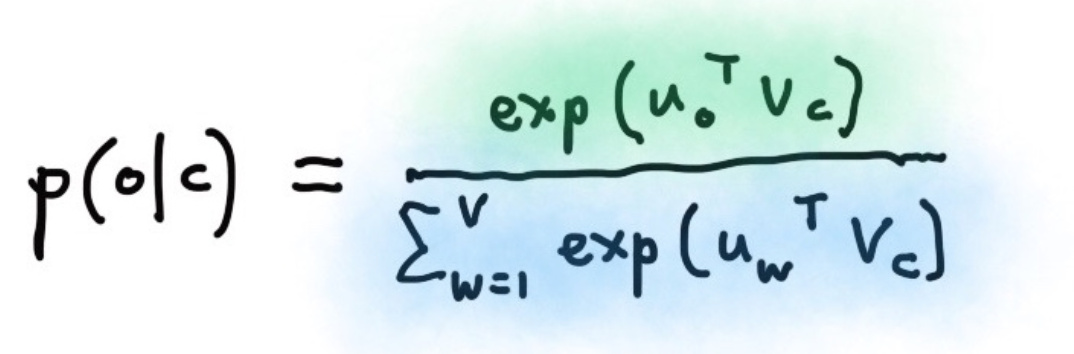
o是输出的上下文词语中的确切某一个,c是中间的词语。u是对应的上下文词向量,v是词向量。
注:关于softmax函数的原理
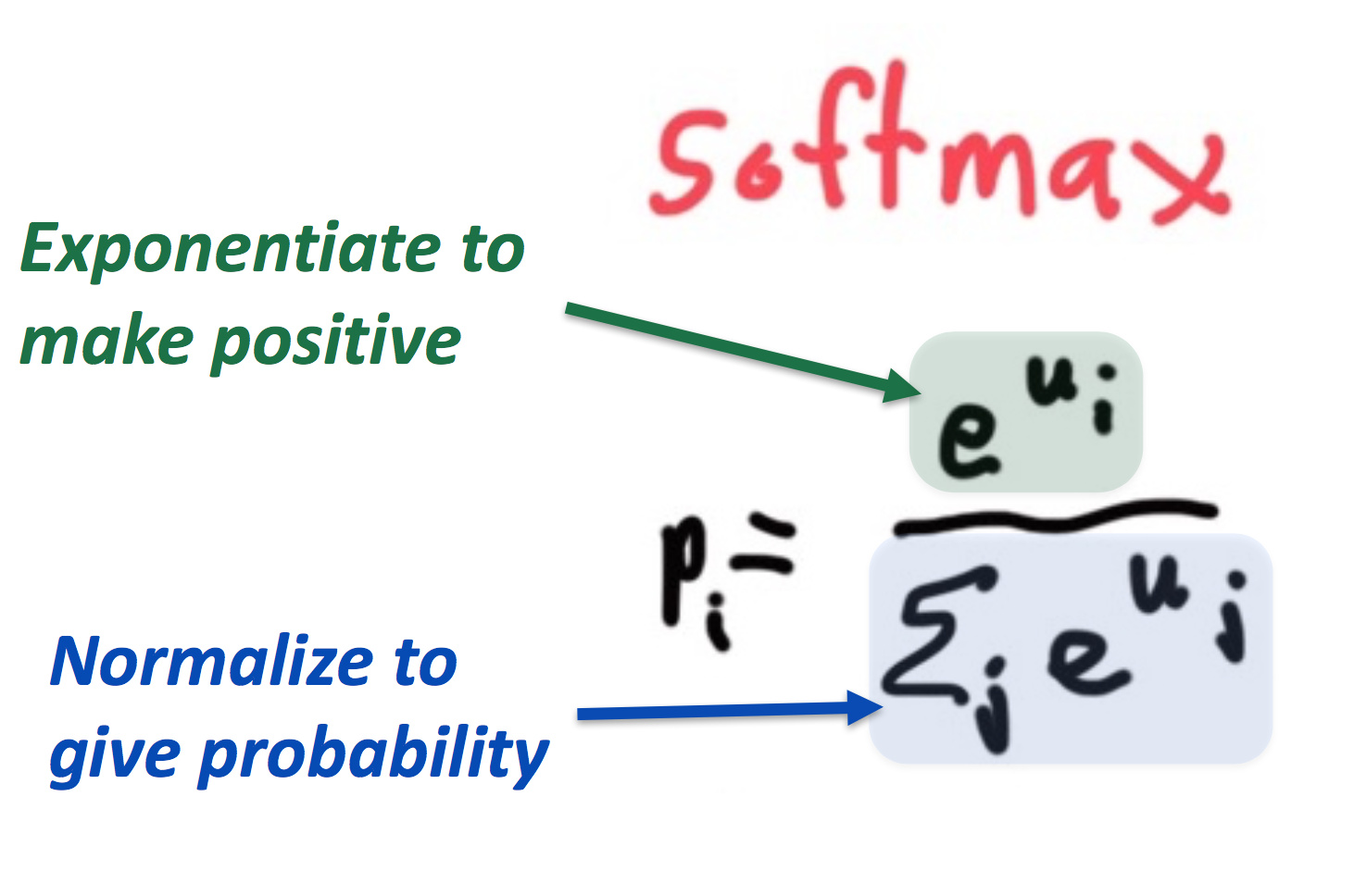
指数函数可以把实数映射成正数,然后归一化得到概率。
softmax之所叫softmax,是因为指数函数会导致较大的数变得更大,小数变得微不足道;这种选择作用类似于max函数。
Skipgram(预测上下文)
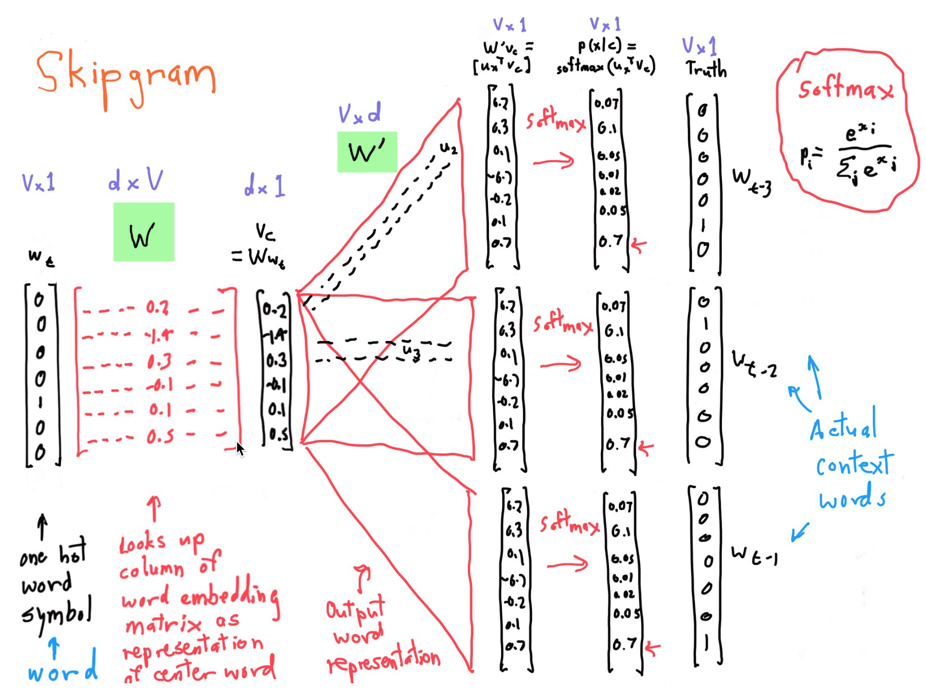
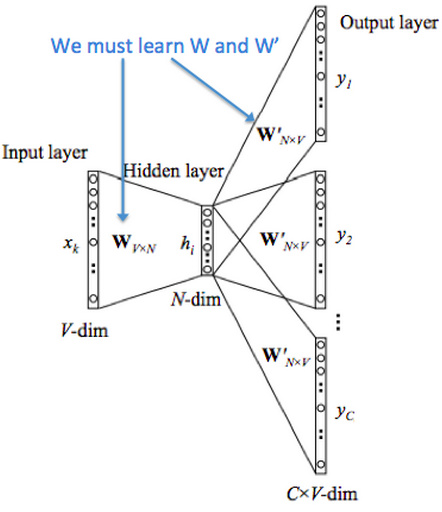
图中各种符号的含义:
- :one-hot向量,对应含义的那一项为1,其他为0.
- W:词向量。这就是我们要求的部分(我们的目的不就是要用一个新的向量来表示一个词嘛,而且这个向量可以反映词与词之间的关系。而W这个矩阵每一个列向量就是一个词的表示。)
- :得到的中心词的词向量
最后用中心词词向量乘以W的转置得到对每个词语的“相似度”,对相似度取softmax得到概率,与答案对比计算损失。
如果不是很明白,可以自己写一个句子带到上面试一试,这里就不具体说明了。
上面手写图的抽象版:
训练模型:计算参数向量的梯度
把所有参数写进向量θθ,对d维的词向量和大小V的词表来讲,有:
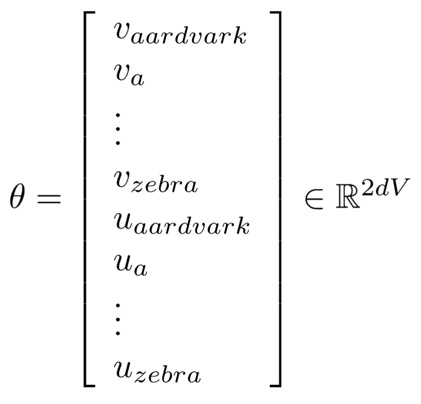
这里上标2是因为上文和下文各有V个备胎
然后用梯度下降法求得参数。
自己手写了一下,懒得打了


连续词袋模型CBOM(这里视频中没有讲,根据一些材料和博客补充一下)
- 对于m个词长度的输入上下文,我们产生它们的one-hot向量。
我们得到上下文的嵌入词向量
将这些向量取平均
- 产生一个得分向量
- 将得分向量转换成概率分布形式y^=softmax(z)
- 我们希望我们产生的概率分布,与真实概率分布相匹配。而y刚好也就是我们期望的真实词语的one-hot向量。
步骤与skip-gram基本一致,不同的是代价函数:
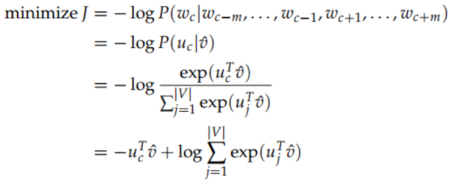
我们可以用随机梯度下降法去更新未知参数的梯度。
参考:http://www.hankcs.com/nlp/word-vector-representations-word2vec.html
http://blog.csdn.net/longxinchen_ml/article/details/51567960