性能改进方法
先放结论,后面再详细写一下原因
| 方法 | 适用范围 |
|---|---|
| 获得更多的训练实例 | 高方差 |
| 减小特征数量 | 高方差 |
| 获得更多特征 | 高偏差 |
| 增加多项式特征(,,等) | 高偏差 |
| 减小归一化程度 | 高偏差 |
| 增加归一化程度 | 高方差 |
评估一个假设
前面我们确定假设函数时所用的方法是不断优化假设函数的参数使其误差最小。但这并不意味着我们求得了一个好的假设函数,因为有可能出现过拟合问题。最简单的确定过拟合的方法就是画图,但当特征数量较多时,画图就比较困难了,所以需要采取别的方法来评判一个假设函数的好坏。
为了检验算法是否过拟合,我们将数据分为训练集和测试集,比例约为7:3。注意数据要随机分配。通过训练集计算出参数后,对测试集运用该模型计算代价函数J。
对于逻辑回归(分类问题),除了采用代价函数计算误差外,还可以用误分类率(misclassfication error)计算。
最后对计算结果求平均
模型选择和交叉验证
前面提到了,当多项式的次数越高时越能适应训练集,但不一定能代表普遍情况(即不能很好的预测)。所以我们通过交叉验证来帮助选择模型。
交叉验证:使用60%的数据用作训练集,20%的数据作为交叉验证集,20%的数据作为测试集
模型选择方法:
- 使用训练集训练出10个模型
- 用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
- 选取代价函数值最小的模型
- 用步骤3选出的模型对测试机计算得出推广误差

诊断偏差和方差
这节讨论的是误差与多项式次数的关系
模型效果不理想一般分为两种情况:
- 偏差较大:表现为欠拟合
- 方差较大:表现为过拟合
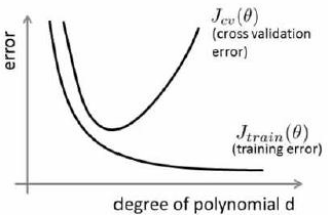
对于训练集,d较小时,拟合程度低,误差大,随着d增大拟合度变好,误差减小
对于交叉验证集,d较小时欠拟合,误差较大,d较大时过拟合,误差也较大,所以呈现出先减小后增大的趋势
所以当训练集误差和交叉验证集误差近似时:偏差/欠拟合
交叉验证误差远大于训练集误差时:方差/过拟合
归一化
这里讨论的是误差与的关系
前面提到我们通过归一化的方式来防止过拟合,但是的值过高会导致欠拟合,过小依然过拟合。
所以我们需要测试一系列的值,通常是0-10之间的呈现2倍关系的值(0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10)。同样把数据分为训练集交叉验证集和测试集
选择的方法:
- 使用训练集训练出12个不同程度的归一化模型
- 分别用每个模型对交叉验证集计算交叉验证误差
- 选择交叉验证误差最小的模型
- 对选出的模型通过测试集得出误差的推广,也可以同时将训练集和交叉验证集的代价函数误差与的值会在一张图表上:
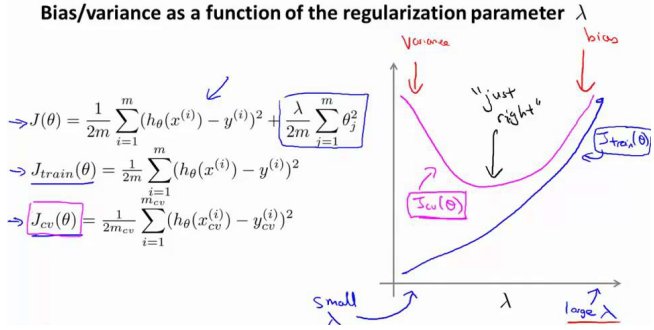
- 较小时,训练误差较小而交叉验证误差较大(过拟合)
- 增加,训练集误差不断增加(欠拟合),而交叉验证集误差先减小后增大
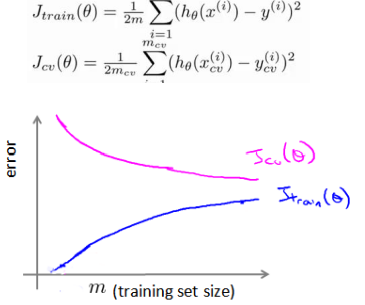
学习曲线
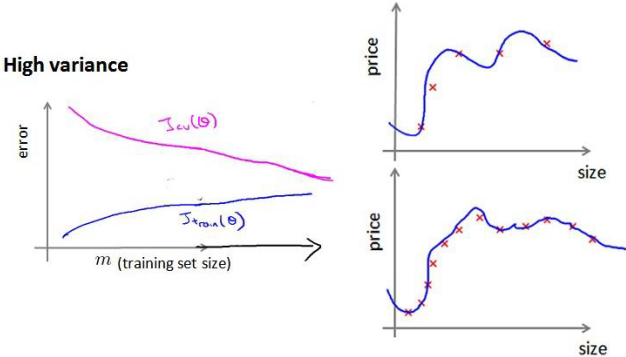
学习曲线是对算法的一个合理检验,表示了训练集实例数量与误差的关系
当实例很少的时候,模型可以完美拟合训练数据,但训练出的模型不能很好的适应交叉训练集。当训练数据增多,训练集的误差会有所增大,但交叉验证集的误差却减小了。
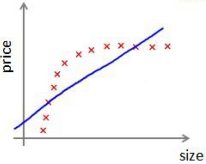
对于高偏差、欠拟合的模型,增加数据量几乎没有效果:
而对于高方差/过拟合的情况,增加训练集数据可以提高准确度:
神经网络和偏差与方差
- 使用较小的神经网络,类似于参数较少的情况,容易造成高偏差和欠拟合。
- 当计算大家较小时使用较大的神经网络类似高方差和过拟合,可以通过归一化来调整
- 所以一般选择较大神经网络并归一化比采用较小的神经网络效果要好
- 对于隐藏层数的选择,通常从一层开始逐渐增加并进行交叉检验。