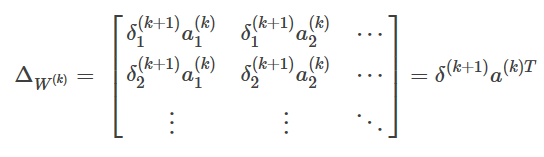分类问题
前面我们讨论了如何构建、训练、评估一个词向量,这些都属于内部性任务。我们构建一个好的词向量的目的还是为了解决实际问题(也叫做外部任务)。下面我们讨论一下处理外部任务的一般方法。
问题描述
大部分nlp的任务都可以看作分类问题,如情感分析,就是判断指代的情况是褒义、贬义还是中性。命名实体识别,就是找出上下文中的中心词的类别。
我们给定一个训练集,是一个d维向量,是一个C维one-hot向量(常用来作为预测结果的标签),N是总数。在一般的机器学习任务中,我们通常固定输入数据和目标标签,通过优化(SGD等)训练权重。在自然语言处理中,我们引入了重训练的思想,针对具体任务时,我们重新训练输入的词向量。下面讨论何时需要进行这样的操作以及原因。
重训练词向量
注:只有在训练集比较大时,才需要进行词向量重训练,否则适得其反
我们一般先用一个简单的内部任务评价来初始化用于外部任务评价的词向量。在很多情况下,这些预训练的词向量的在外部任务中的表现已经非常好了。 然而,一些情况下,这些词向量在外部任务中的表现仍然有提升空间。不过,重训练词向量是由风险的。
比如有一个给单词做情感分析的小任务,在预训练的词向量中,这三个表示电视的单词都是在一起的:
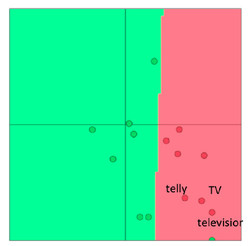
但由于情感分析语料中,训练集只含有TV和telly,导致re-training之后两者跑到别处去了:
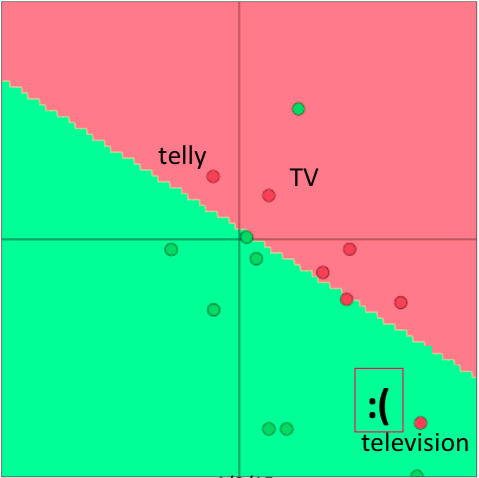
于是在测试集上导致television被误分类。
这个例子说明,如果任务的语料非常小,则不必在任务语料上重新训练词向量,否则会导致词向量过拟合。
softmax与正则化
softmax分类函数:
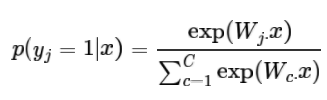
计算方法分为两个步骤:取权值矩阵的某一行乘上输入向量,归一化得到概率。
上面我们计算了词向量x属于类别j的概率。训练的时候,可以直接最小化正确类别的概率的负对数:
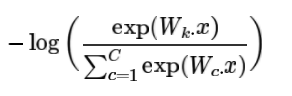
其实这个损失函数等效于交叉熵:
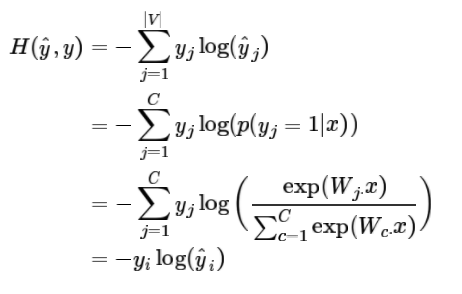
这是因为类别是one-hot向量。只有正确的分类y=1,其余y=0
对N个数据点来讲有:
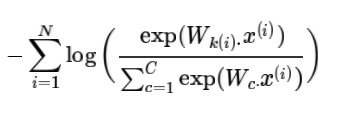
这个公式有一点点不同,注意到其实这里的k(i)现在是个函数,返回每个x(i)所对应的正确的类。
如果我们同时要训练模型中的权重参数(W)和词向量(x), 需要训练多少个参数呢? 一个以d-维词向量为输入,输出一个其在C个类上的分布的简单的线性模型需要C·d个参数。如果我们训练时更新词库中每个单词的词向量,则需要更新|V|个词向量,而每一个都是d维。综合一下,我们知道,一个简单的线性分类模型需要更新C⋅d+∣V∣⋅d个参数。
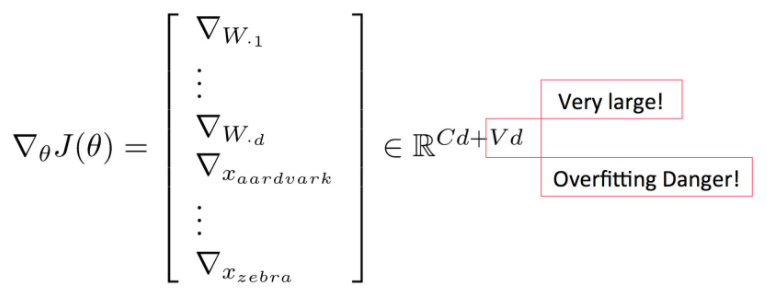
对于一个简单的线性模型来说,这个参数量就显得非常大了,带来的问题是模型很容易在数据集上过拟合。为了缓解过拟合,我们需要引入一个正则项,用贝耶斯的角度来讲,这个正则项其实就是一个给模型的参数加上了一个先验分布,从而希望他们的值更接近0。
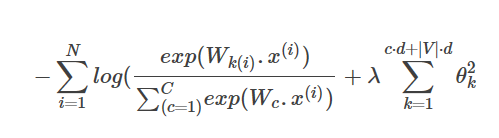
如果咱们找到合适的正则项权重λ,那最小化上面的损失函数得到的模型,不会出现某些权重特别大的情况,同时模型的泛化能力也很不错。
词窗分类
我们这里看到的是一个中心词,和长度为2的左右窗口内的词。这种上下文可以帮助我们分辨Paris是一个地点,还是一个人名
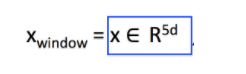
我们前面提到的外部任务都是以单个单词为输入的。实际上,由于自然语言的特性,这种情况很少会出现。在自然语言中,有很多一词多义的情况,这时候我们一般会参考上下文来判断。所以在大多数的情况下,我们给模型输入的是一个词序列。这个词序列由一个中心词向量和它上下文的词向量组成。上下文中词的数量又叫词窗大小,任务不同这个参数的取值也不同。一般来讲,小窗口在句法上的精度较高,大窗口在语义上的表现较好。
softmax
我们继续使用softmax进行分类。只需要将之前的换成即可

那相应的,我们计算损失函数梯度的时候,得到的就是如下形式的向量了:
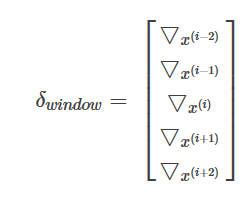
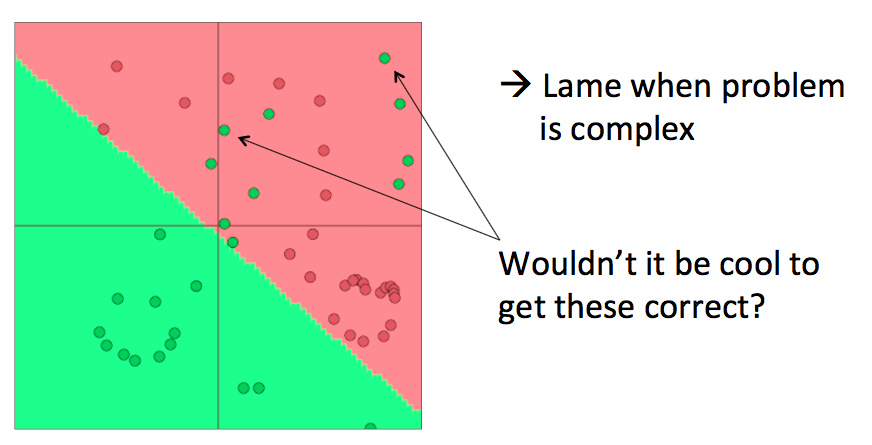
对于较小的数据集,能勉强提供一个线性分类决策边界
神经网络
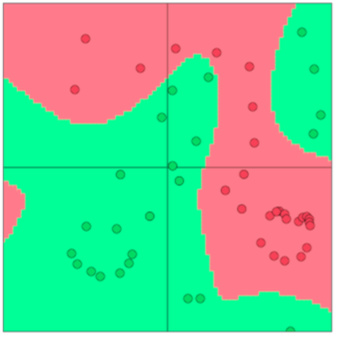
神经网络可以提供非线性的决策边界:
神经网络
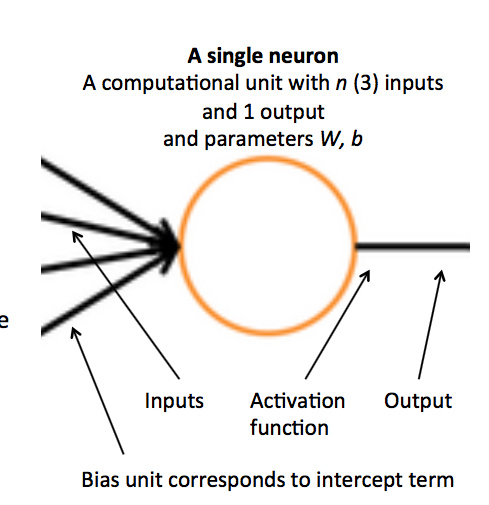
之前已经写过几个神经网络的笔记,这里就简单写一写。
基础概念
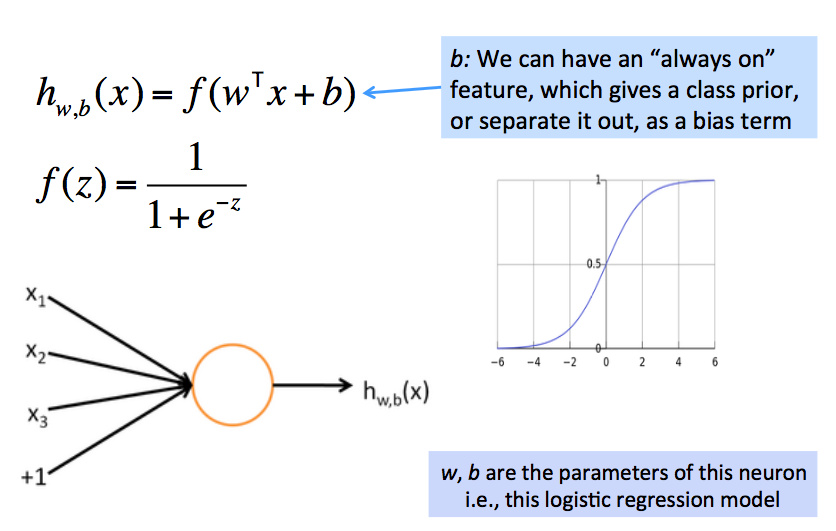
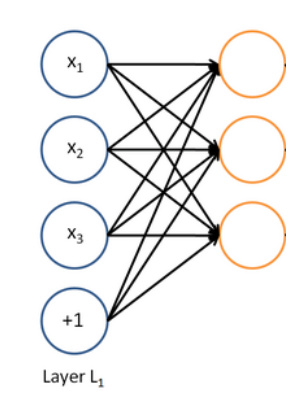
我们把预测结果喂给下一级逻辑回归单元,由损失函数自动决定它们预测什么:
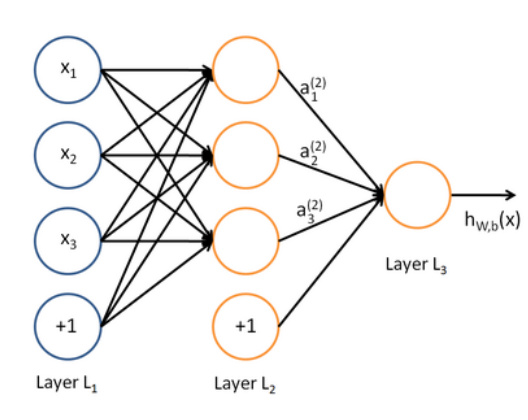
多层网络:
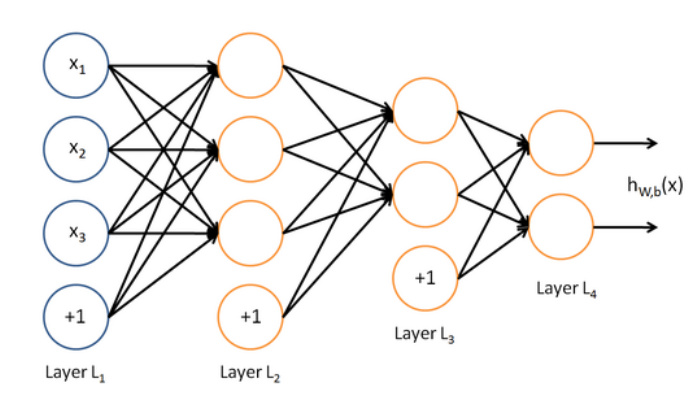
前向传播
我们以一个实际例子来观察前向和后向传播在nlp中的作用。
一个命名识体识别的例子:
“Museums in Paris are amazing”
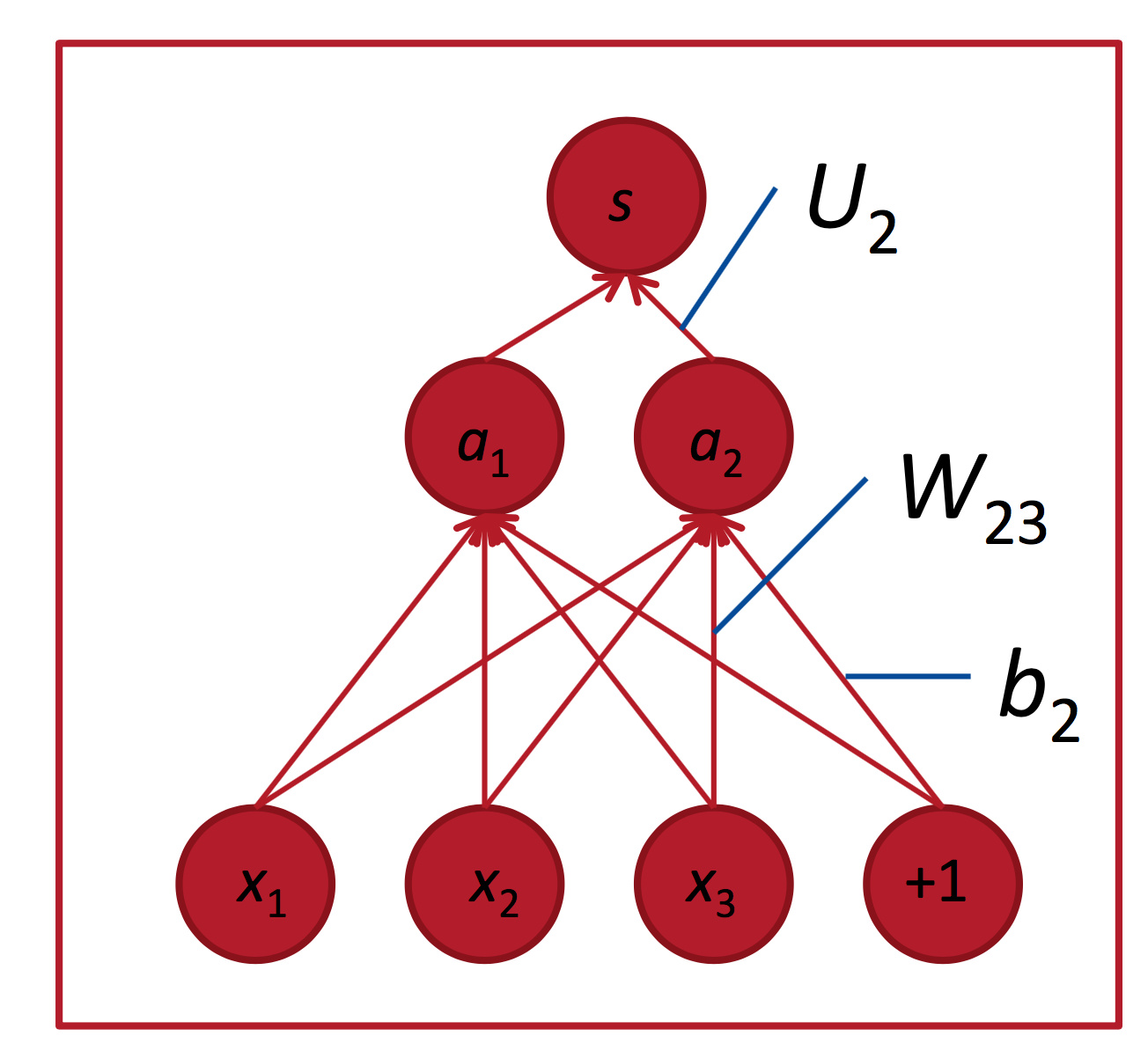
我们要来判断这里的中心词”Paris”是不是个命名实体。在这种情况下, 我们不止要知道这个词窗内哪些词向量出现过,可能也需要知道他们之间的相互作用。 比如说,可能只有在”Museums”出现在第1个位置,”in”出现在第二个位置的时候,Paris才是命名实体。如果你直接把词向量丢给Softmax函数, 这种非线性的决策是很难做到的。
所以我们需要用1.2中讨论的方法对输入的变量进行非线性的处理加工(神经元产出非线性激励输出),再把这些中间层的产物输入到Softmax函数中去。 这样我们可以用另一个矩阵
U∈,与激励输出结果运算生成得分(当然,这里是未归一化的),从而进一步用于分类任务:
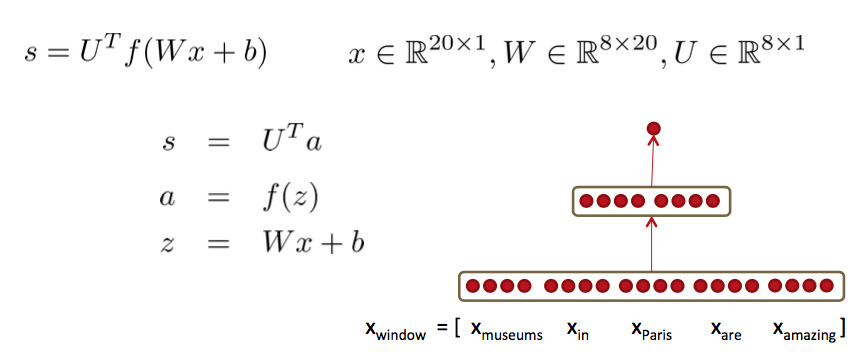
最大化目标间隔函数
跟大多数机器学习模型一样,神经网络也需要一个优化目标,一个用来衡量模型好坏的度量。优化算法在做的事情呢,通常说来就是找到一组权重,来最优化目标或者最小化误差。这里我们讨论一个比较流行的度量,叫做最大化间隔目标函数。直观的理解就是我们要保证被正确分类的样本分数要高于错误分类的样本得分。
继续用之前的例子,如果我们把一个正确标记的词窗 “Museums in Paris are amazing”(这里Paris是命名实体)的得分记做,而错误标记的词窗“Not all Museums in Paris”(这里Paris不是命名实体)的得分记作 (c表示这个词窗”corrupt”了)
于是,我们的目标函数就是要最大化 或者最小化 。然而时,这表明标记正确,我们可以跳过这个样不进行训练。我们只需要将的样本训练到差最小就可以了。所以目标函数改进为:
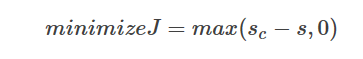
但是这个优化函数还不稳妥,因为它缺乏一个用来保证安全划分的间隔。我们希望那些被正确标记的词窗得分不仅要比错误标记的词窗得分高,还希望至少高出一个取值为正的间隔Δ。通常将取1。因此,我们修改优化目标为 ︰
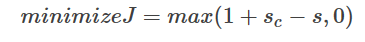
这实际上是将函数间隔转换为几何间隔。可以参考SVM优化函数的几何意义。
通常通过负采样算法得到负例。
这个目标函数的好处是,随着训练的进行,可以忽略越来越多的实例,而只专注于那些难分类的实例。
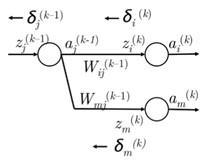
反向传播训练
通过反向传播来训练模型中的各个参数。方法就是梯度下降:
通过下面一个简单的网络我们自己推导一遍:

假设目标函数取正值,我们希望更新权重参数我们注意到只在计算和的时候出现。这一点对于理解反向传播很重要-参数的反向传播梯度只被那些在正向计算中用到过这个参数的值所影响。在之后的正向计算中和相乘进而参与到分类得分的计算中。
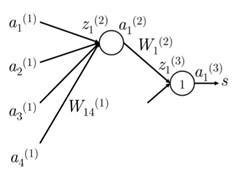
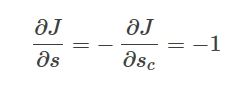
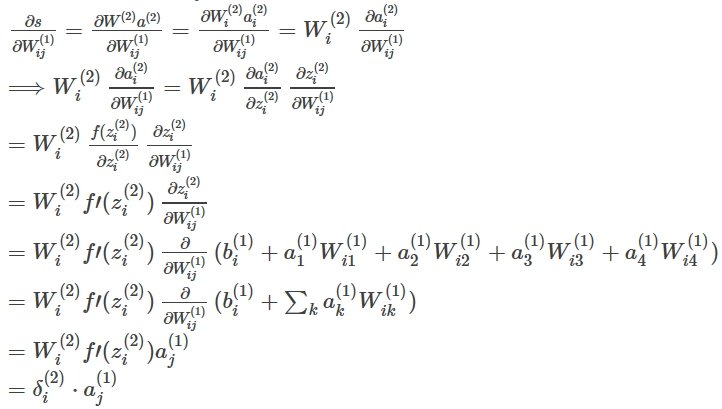
这里所谓的反向传播误差其实就是最终的目标函数对于第k层上第i个激励输出值的导数
如我们要更新
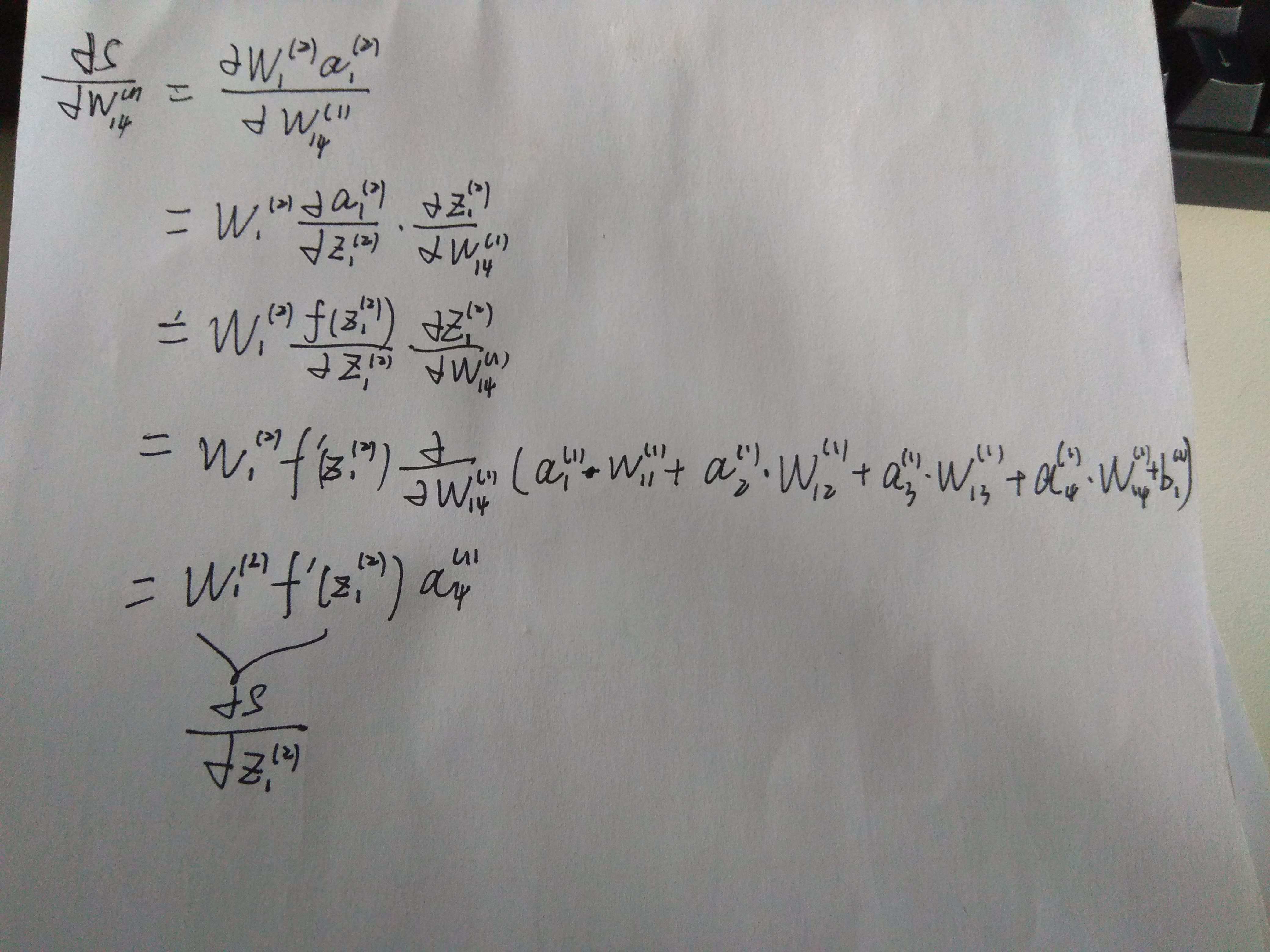
偏移量的更新
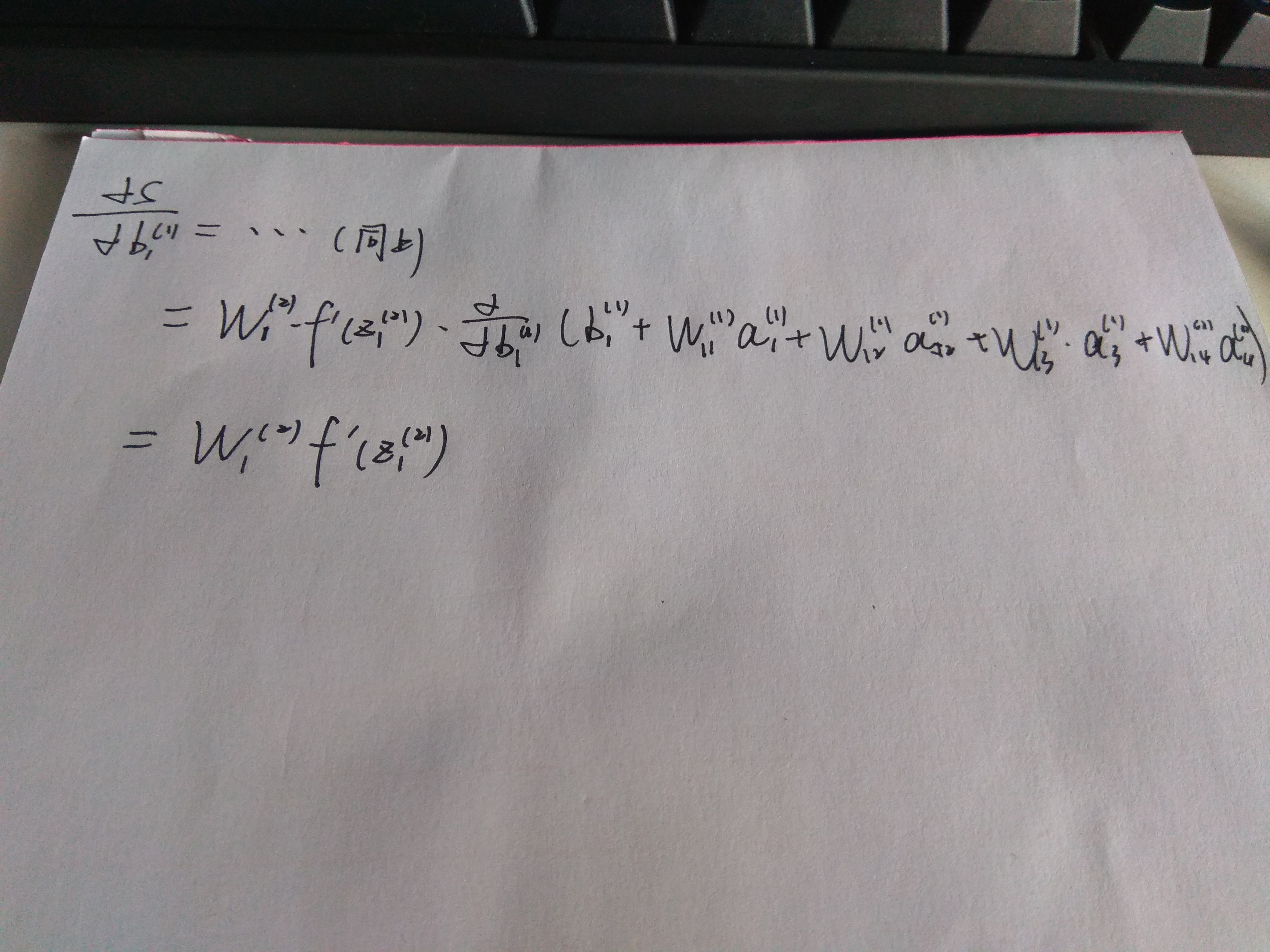
反向传播的向量化