LDA
LDA的全称是Linear Discriminant Analysis(线性判别分析),是一种supervised learning。LDA的原理是,将带标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,相同类别的点,将会在投影后的空间中更接近。要说明白LDA,首先得弄明白线性分类器(Linear Classifier):因为LDA是一种线性分类器。对于K-分类的一个分类问题,会有K个线性函数:
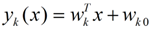
当满足条件:对于所有的j,都有Yk > Yj,的时候,我们就说x属于类别k。对于每一个分类,都有一个公式去算一个分值,在所有的公式得到的分值中,找一个最大的,就是所属的分类了。
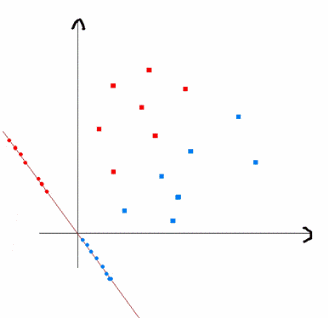
上式实际上就是一种投影,是将一个高维的点投影到一条高维的直线上,LDA最求的目标是,给出一个标注了类别的数据集,投影到了一条直线之后,能够使得点尽量的按类别区分开,当k=2即二分类问题的时候,如下图所示:
下面推到一下二分类LDA问题的公式:
假设用来区分二分类的直线(投影函数)为: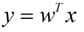
LDA分类的一个目标是使得不同类别之间的距离越远越好,同一类别之中的距离越近越好(即需要找一个最佳的w的值),所以我们需要定义几个关键的值。
类别i的原始中心点为:(Di表示属于类别i的点)
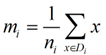
类别i投影后的中心点为:
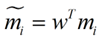
衡量类别i投影后,类别点之间的分散程度(方差)为:
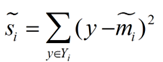
最终我们可以得到一个下面的公式,表示LDA投影到w后的损失函数:
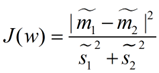
我们分类的目标是,使得类别内的点距离越近越好(集中),类别间的点越远越好。分母表示每一个类别内的方差之和,方差越大表示一个类别内的点越分散,分子为两个类别各自的中心点的距离的平方,我们最大化J(w)就可以求出最优的w了。想要求出最优的w,可以使用拉格朗日乘子法,但是现在我们得到的J(w)里面,w是不能被单独提出来的,我们就得想办法将w单独提出来。
我们定义一个投影前的各类别分散程度的矩阵,矩阵的含义是,如果某一个分类的输入点集Di里面的点距离这个分类的中心店mi越近,则Si里面元素的值就越小,如果分类的点都紧紧地围绕着mi,则Si里面的元素值越更接近0.
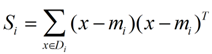
Si称作散列矩阵(scatter matrix)
同时定义,Sw叫做within-class scatter matrix
带入Si,将J(w)分母化为:(图片中应为si的平方)
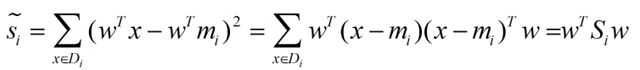
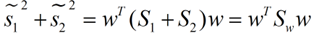
同样的将J(w)分子化为:
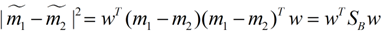
成为Between-class-scatter,是一个秩为1的矩阵
这样损失函数可以化成下面的形式:
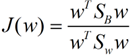
然后就可以求导来求J(w)的最大值从而得到最佳的w。在我们求导之前,需要对分母进行归一化,因为不做归一的话,w扩大任何倍,都成立,我们就无法确定w。因此我们打算令
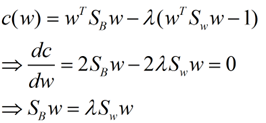
其中用到了矩阵微积分,求导时可以简单的把看作
如果可逆,两边同乘得到
w就是矩阵的特征向量
这个公式称为Fisher linear discrimination。
将前面已知的公式带入得到
由于对w扩大缩小任何倍不影响结果,因此可以约去两边的未知常数和,得到
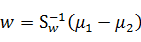
至此,我们只需要求出原始样本的均值和方差就可以求出最佳的方向w
对于N(N>2)分类的问题,结论:
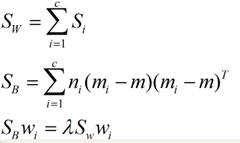
参考:
http://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html