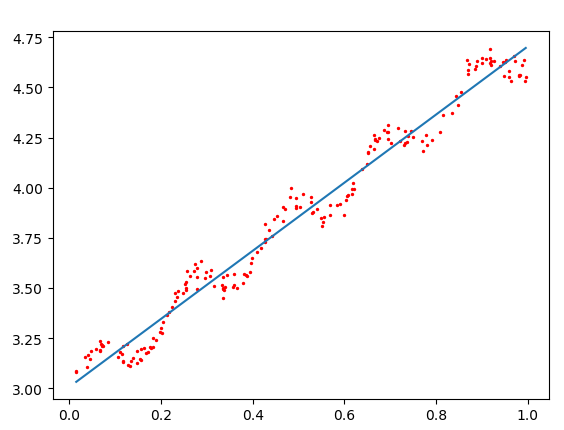
基本的线性回归
1 | import numpy as np |
具体理论之前都已经写过,简单的说就是将平方误差最小化的过程。将上式向量化,用矩阵表示为,对求导得到,令其等于0,解出w
值得注意的是代码中要先验证是否可逆
运行结果:
1 | #-*-coding:utf-8 -*- |
局部加权的线性回归(Locally Weighed Liner Regression,LWLR)
该方法用来避免欠拟合问题,所以通过引入一些偏差来降低方差
回归系数公式
其中W是一个矩阵,用来给每个数据点赋予权重
LWLR使用核(与SVM类似)来赋予权重。
常用的是高斯核
这样就构建了一个只含对角元素的权重矩阵%并且点x与x(i)越近,w(i,i)将 会 越 大 。
上
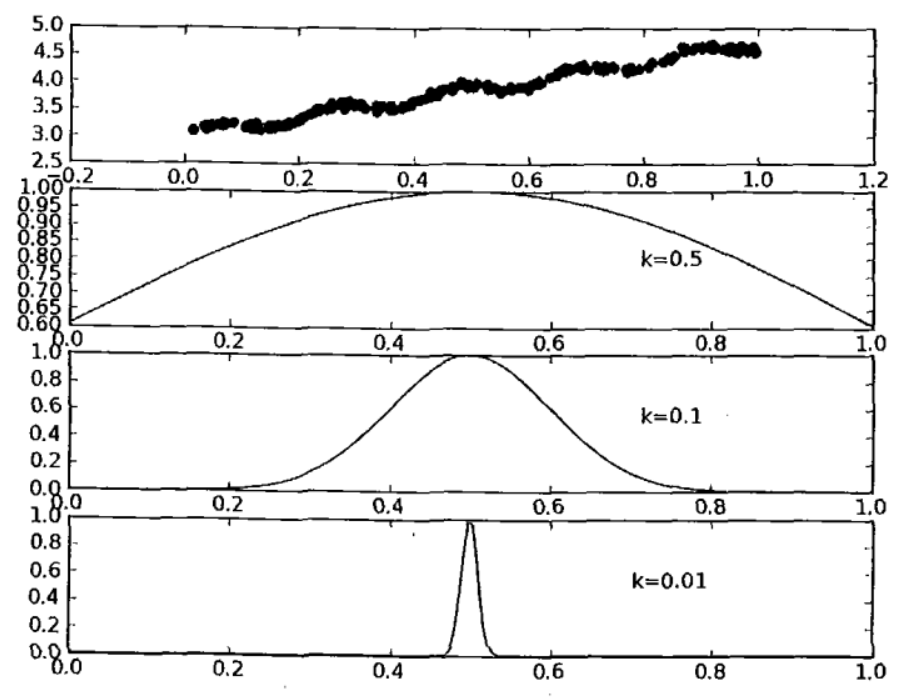
述公式包含一个需要用户指定的参数、 它决定了对附近的点赋予多大的权重,这也是使用LWLR时唯一需要考虑的参数,在图8-4中可以看到参数k与权重的关系。
1 | def lwlr(testPoint,xArr,yArr,k=1.0): |
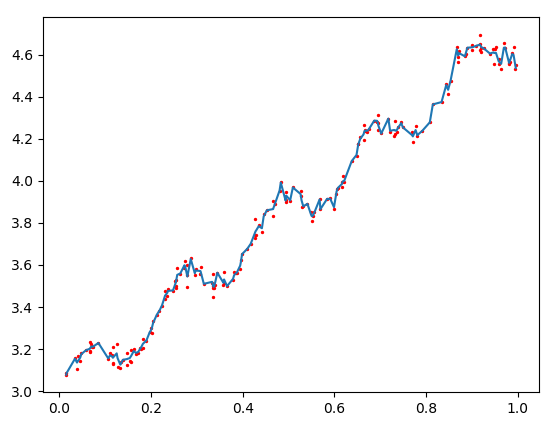
该程序的作用给定空间中的任意一点,计算出对应的预测值yHat。,读入数 据 并创建所需矩阵,之后创建对角权重矩阵weightsO.权重矩阵是一个方阵,阶数等于样本点个数。也就是说,该矩阵为每个样本点初始化了一个权重。接着,算法将遍历数据集,计算每个样本点对应的权重值:随着样本点与待预测
点距离的递增,权重将以指数级衰减0 。输人参数k控制衰减的速度。与之前的函数standRegress()一样,在权重矩阵计算完毕后,就可以得到对回归系数呢的一个估计。
运行程序
1 | #-*-coding:utf-8 -*- |
k=0.003
k=0.01
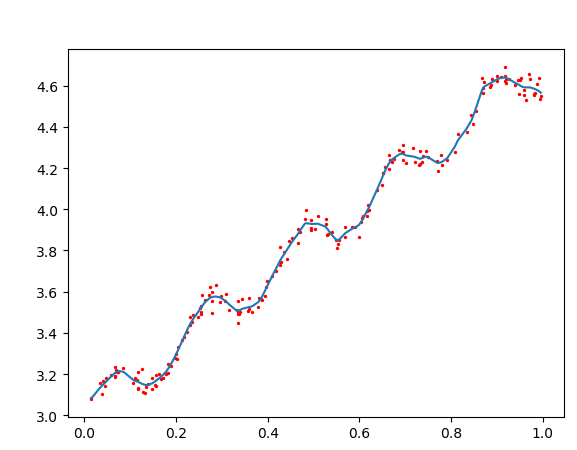
k=0.1
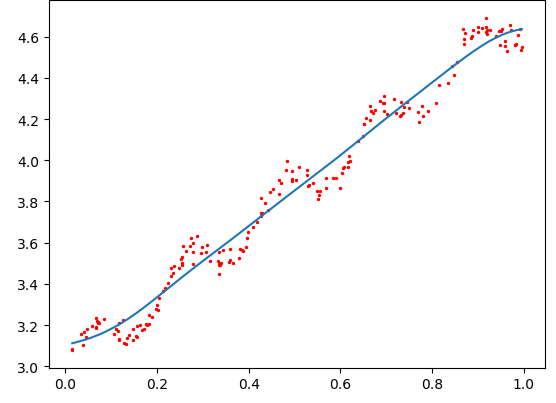
k=1