一、概述
简单的说KNN是通过测量某样本与已知样本的距离来进行分类的。
工作原理如下:
首先我们有一个带标注的训练样本集。当我们输入一个新的样本,将新样本的每个特征与训练样本集中数据的对应特征进行比较。选择k个在坐标系中与新样本最接近的数据,这些数据中出现次数最多的分类即可看作新数据的分类。
通常k<=20
如我们要下图绿色图形的分类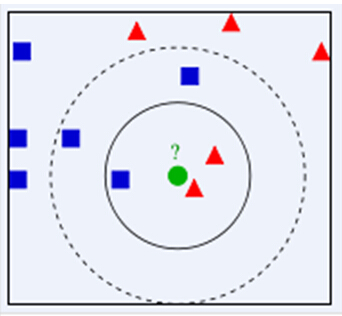
如果k=3 则被分类为三角形
如果k=5 则被分类为正方形
所以knn算法的结果很大程度上取决于k的选择
knn算法的描述:
- 列表项
- 计算测试数据与各个训练集之间的距离
- 按照距离的递增关系进行排序
- 选取距离最小的k个点
- 确定前k个点所在类别的频率
- 返回前k个点出现频率最高的类别作为测试数据的分类
特点:
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用范围:数值型和标称型
二、python实现
1 |
|
三、总结
这是《机器学习实战》书中的第一个算法,实现起来比较简单。书中有几个实战的内容就不详细写了,代码都已放在github上。
这个算法中用到了Numpy和Matplotlib库,对这些库的使用还需要继续学习(会新开一篇写一下常用的用法)