1.数据压缩
如果几个特征高度相关,我们可以用1个特征进行表示,这就是降维
降维可以对数据进行压缩,节约存储空间,并提高训练速度
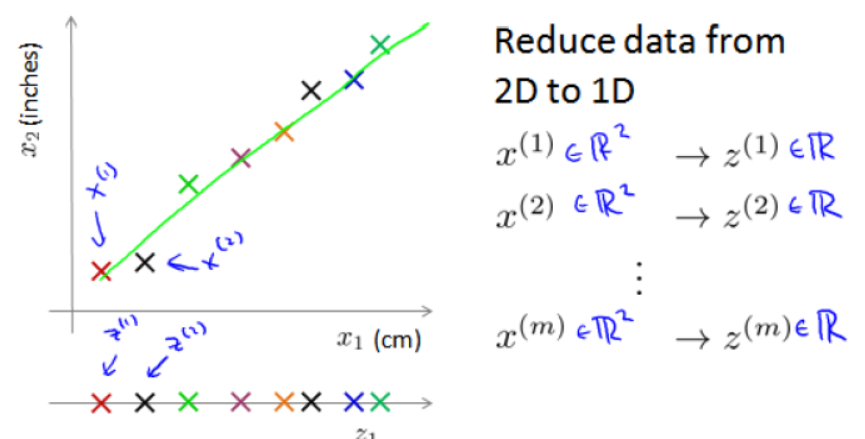
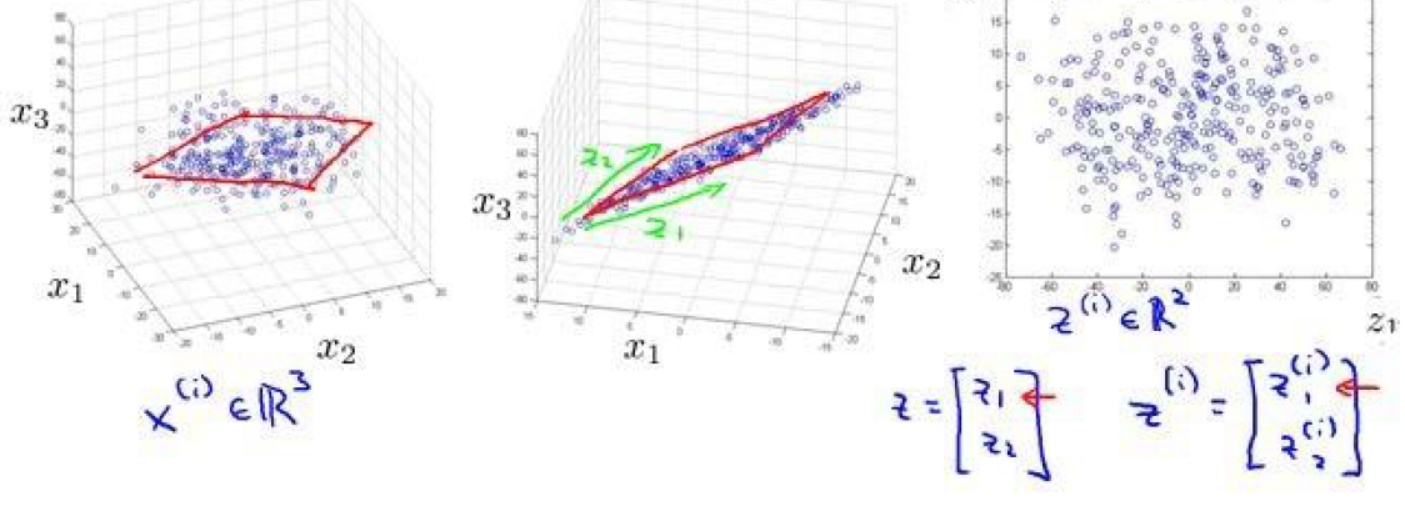
2.数据可视化
可以通过降维将数据进行可视化
3.主成成分分析(Principal Component Analysis Problem Formulation)
PCA是最常见的降维算法
在 PCA 中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据
都 投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原
点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
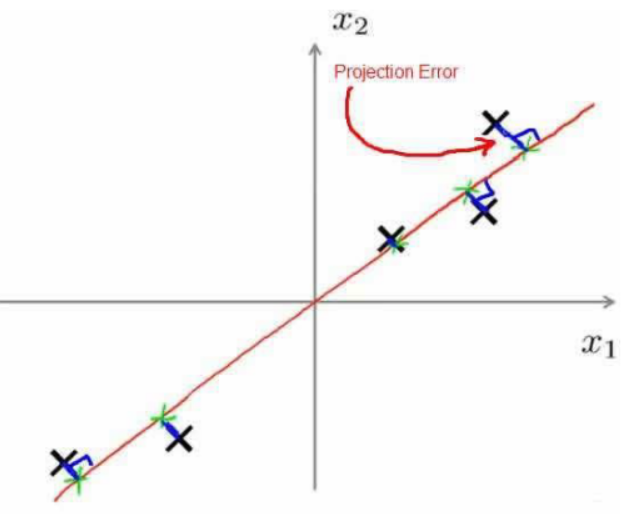
下面给出主成分分析问题的描述:
问题是要将 n 维数据降至 k 维,目标是找到向量 u (1) ,u (2) ,…,u (k)使得总的投射误差最小。
主成分分析与线性回顾的比较:
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是投射误差(Projected
Error),而线性回归尝试的是最小化预测误差。线性回归的目的是预测结果,而主成分分析
不作任何预测。
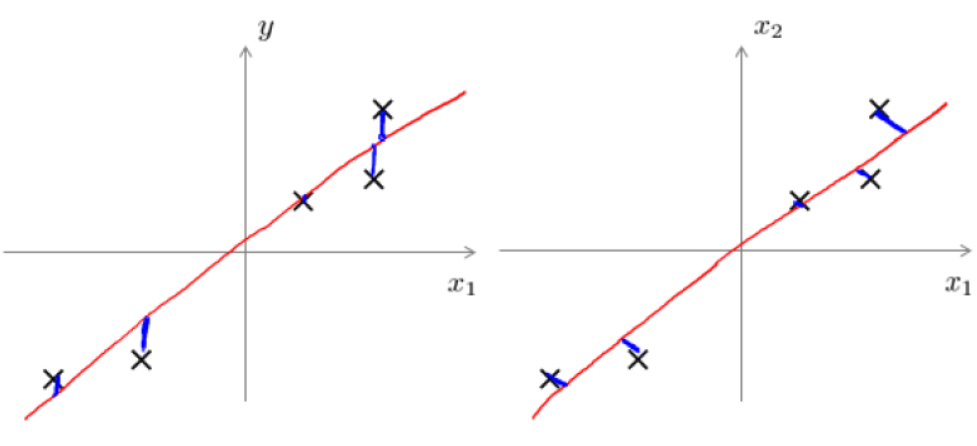
上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)
4.主成分分析算法
PCA减少n维到k维:
第一步是均值归一化。我们需要计算出所有特征的均值,然后令。如果特征是在不同的数量级上,我们还需要将其除以标准差。
第二步是计算协方差矩阵(covariance matrix)Σ:
第三步是计算协方差矩阵 Σ 的特征向量(eigenvectors):
利用Ocatave里的奇异值分解来求解。[U,S,V]=svd(sigma)。
$$U=\begin{bmatrix}
{\vdots}&{\vdots}&{\cdots}&{\vdots}\\
u^1&u^2&{\cdots}&u^n\\
{\vdots}&{\vdots}&{\cdots}&{\vdots}\\
\end{bmatrix}$$
对于一个 n×n 维度的矩阵,上式中的U是一个具有与数据之间最小投射误差的方向向量构成的矩阵。如果我们希望将数据从 n 维降至 k 维,我们只需要从 U 中选取前 K 个向量,获得一个 n×k 维度的矩阵,我们用 表示,然后通过如下计算获得要求的新特征向量z (i):
其中 x 是 n×1 维的,因此结果为 k×1 维度。注,我们不对方差特征进行处理。
5.选择主成分的数量
主要成分分析是减少投射的平均均方误差:
训练集的方差为:
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的 K 值。
我们可以先令 K=1,然后进行主要成分分析,获得 U reduce 和 z,然后计算比例是否小于 1%。如果不是的话再令K=2,如此类推,直到找到可以使得比例小于 1%的最小 K 值(原因是各个特征之间通常情况存在某种相关性)。
还有一些更好的方式来选择 K,当我们在Octave中调用“svd”函数的时候,我们获得三个参数:[U, S, V] = svd(sigma)。
其中的 S 是一个 n×n 的矩阵,只有对角线上有值,而其它单元都是 0,我们可以使用这
个矩阵来计算平均均方误差与训练集方差的比例:
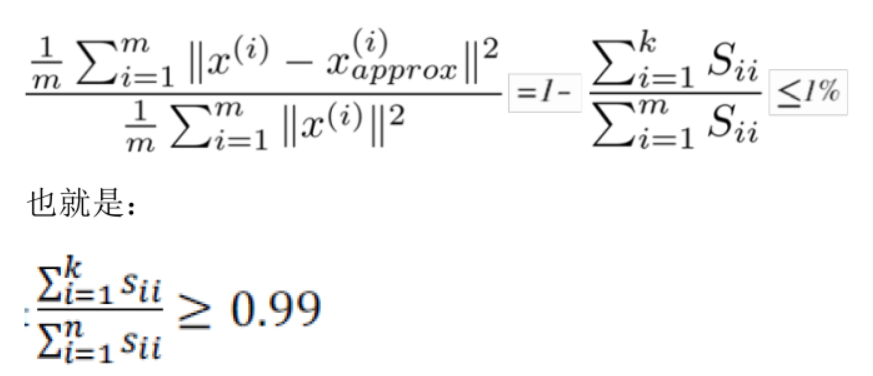
6.压缩重建
7.应用建议:
只在训练集使用主成分析
最好不要用作避免过拟合的手段