1.k-均值算法
k-均值是一个迭代算法,假设我们想将数据聚类为n组,方法为:
- 选择k个随机的点,称为聚类中心
- 对于数据集中的每一个数据,按照距离k个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类。
- 计算每一个组的平均值,将该组所关联的中心点移到平均值的位置
- 重复上述步骤直到中心点不再变化
示例:
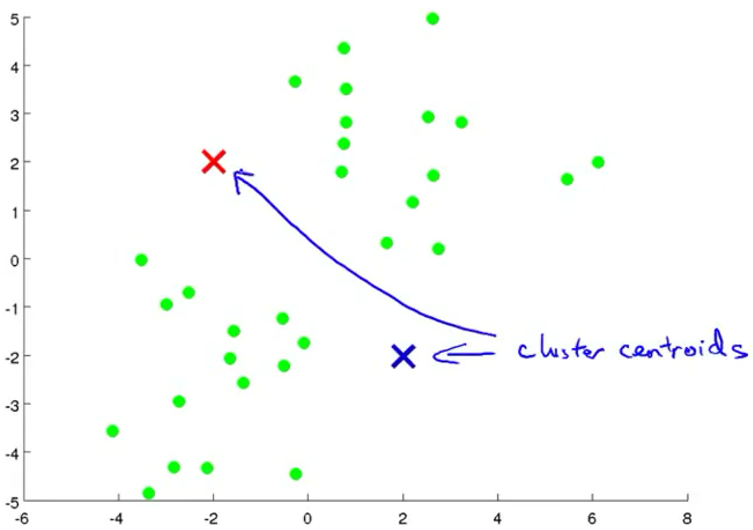
开始随机选两个聚类中心
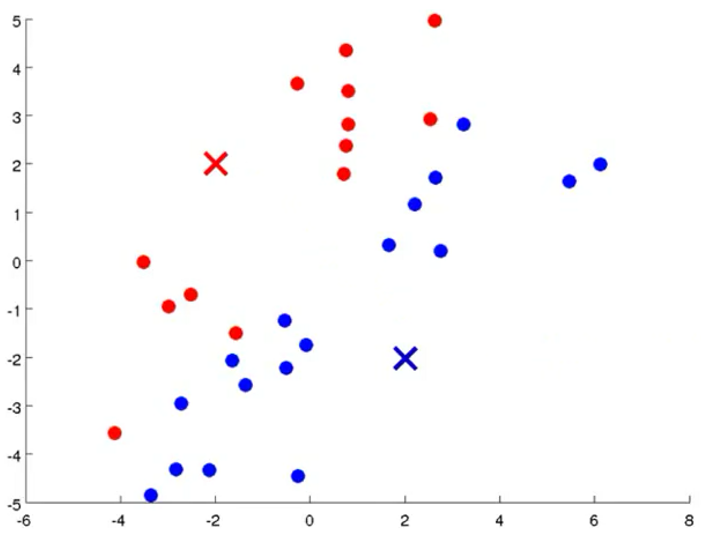
将数据与聚类中心关联起来,分成了两类
第一次迭代,移动聚类中心
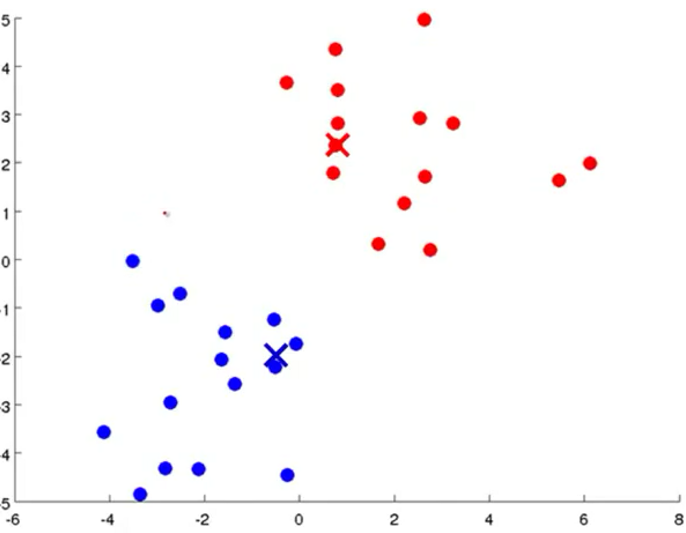
继续迭代,直到聚类中心不再变化
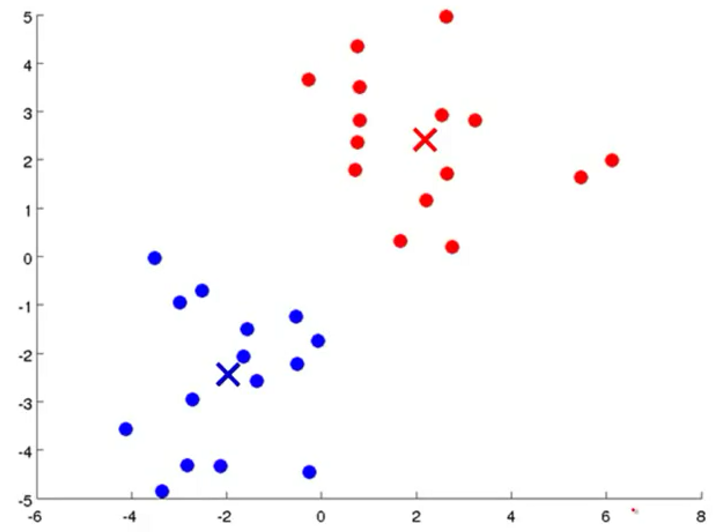
用 来表示聚类中心,用 来储存与第i个实例数据最近的聚类中心的索引,算法如下:
1 | Repeat { |
2.优化目标
K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,
因此 K-均值的代价函数(又称畸变函数 Distortion function)为:
我们的的优化目标便是找出使得代价函数最小
的 c (1) ,c (2) ,…,c (m)和 μ 1 ,μ 2 ,…,μ k:
上一节的算法,第一个循环是用于减小 c (i)引起的代价,
而第二个循环则是用于减小 μ i 引起的代价。
3.随机初始化
在运行 K-均值算法的之前,我们首先要随机初始化所有的聚类中心点:
我们应该选择 K<m,即聚类中心点的个数要小于所有训练集实例的数量
随机选择 K 个训练实例,然后令 K 个聚类中心分别与这 K 个训练实例相等
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情
况。
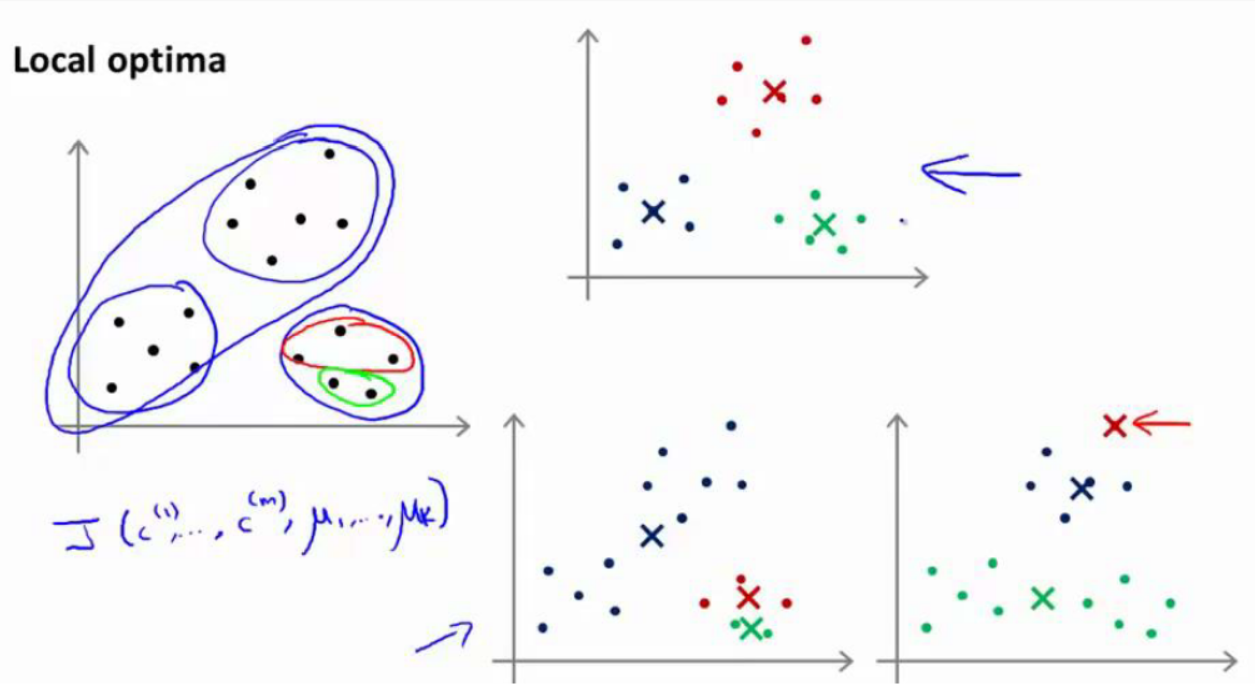
为了解决这个问题,我们通常需要多次运行 K-均值算法,每一次都重新进行随机初始
化,最后再比较多次运行 K-均值的结果,选择代价函数最小的结果。这种方法在 K 较小的时候(2–10)还是可行的,但是如果K较大,这么做也可能不会有明显地改善。
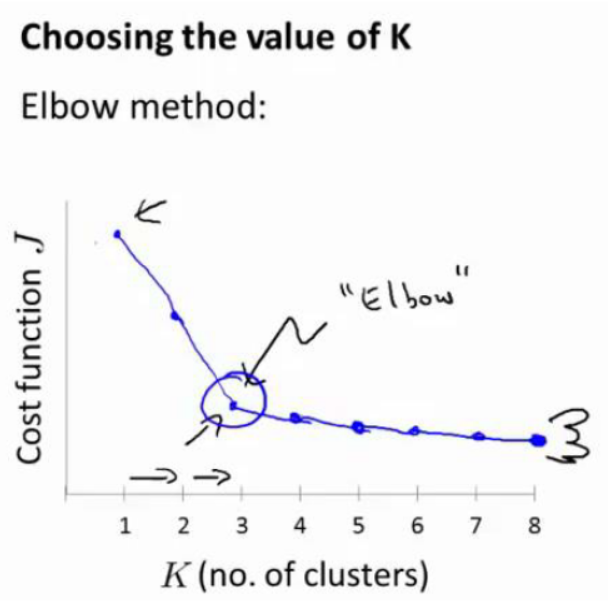
4.选择聚类数
通常根据具体问题人工手动选择。
肘部法则: