误差分析
- 开始时先构建一个简单的(特征量少)系统,快速得到一个结果,并进行交叉验证
- 画出学习曲线,找出算法存在的问题逐步改进,决定增加数据、添加特征或其他方法
- 当不容易画出学习曲线时我们可以采用误差分析的方法,即人工检查交叉检验集中在算法中产生误差的实例,看看这些实例是否有某种趋势
通过量化的数值(如误差率)而不是凭感觉改进算法。同时注意是在交叉验证集上做误差分析,而不是测试集。
类偏斜
假如我们要用算法来预测恶性癌症,训练集中只有0.5%的实例是恶性肿瘤。假设我们的算法有1%的误差。所以“假设所有肿瘤都是良性的”的误差比通过算法来预测的误差还要小。
像上述例子这样,训练集中有非常多的同一种类实例,只有很少或没有其他类实例的情况,叫做类偏斜。
对于类偏斜情况,用误差大小评判算法就不是一个很好的依据了,因此我们通过查准率(precision)和查全率(recall)来作为算法的评价标准。
预测结果可以分为以下四类
| 实际\预测 | 0 | 1 | |
|---|---|---|---|
| 0 | 正确否定(True Negativ,TN) | 错误否定(False Negative,FN) | |
| 1 | 错误肯定(False Positive,FP) | 正确肯定(True Positive,TP) |
precision=TP/(TP+FP)
所有预测患有恶性肿瘤的病人中,实际患有恶性肿瘤的病人百分比。
recall=TP/(TP+FN)
实际患有恶性肿瘤的病人中,成功预测的百分比。
precision和recall越高越好
查全率和查准率之间的权衡

如果我们只希望在非常确信的情况下预测为真,可以将0.5调整为0.7,0.9。可减少错误预测的情况,但会增加未能成功预测的情况。
如果我们想尽可能将所有患恶性肿瘤的病人都预测到,可以将0.5调整为0.3等
将不同阈值下查全率和查准率的关系绘成图表:
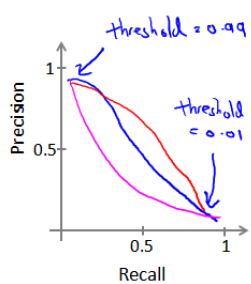
可以通过计算值来帮助我们选择阈值
选择使得F1最大的阈值
机器学习的依据
有时(如低偏差的情况)低性能的算法在大数据量的情况下比高性能算法但是数据量少表现要好
对于大量训练数据作用的两种理解方式:
- 即使特征参数数量非常多,只要训练集足够大(比参数数量还多),依然可以很好的拟合,还能避免过拟合,使训练误差很低,同时训练误差接近测试误差
- 为了获得一个高性能算法,我们不希望高偏差和方差。可以通过一个具有很多参数的算法来达到低偏差,同时用非常大的训练集来保证没有方差问题。所以一个有很多参数同时有大量数据训练出的算法是得到高性能算法的一个很好的方式