终于放假了,也有时间写博客了。最近在看西瓜书,记一下自己的理解和笔记。比较基础的内容已经在Coursera的机器学习课程笔记中写过了,为了节约时间就不再赘述了,只记一些之前课程里没有深入到的概念。
绪论就不写了,直接从第二章模型评估开始写吧。
2.1 经验误差与过拟合
【错误率】:分类错误的样本数占样本总数的比例。
【精度】:分类正确的样本数占样本总数的比例。即:精度=1-错误率。
【训练误差】:学习器在训练集上的误差,也叫【经验误差】
【泛化误差】:学习器在新样本上的误差
2.2评估方法
需要一些评估方法的原因:泛化误差无法直接获得,训练误差过拟合不适合作为评估标准。
方法:将数据集分为训练集和测试集,用【测试误差】作为泛化误差的近似。
几种划测试集的方法:
留出法
直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即D=S∪T,S∩T=∅。
要求:
- 集合互斥
- 保持数据分布的一致性,即分层采样
- 单次使用留出法得到的结果往往不稳定可靠,一般采用若干次随机划分,重复进行实验评估后取平均值作为留出法的评估结果。
交叉验证法
先将数据集D分为k个大小相似的互斥子集,即。每个子集Di都尽可能保持数据分布的一致性,即每个子集仍然要进行分层采样。每次用k-1个子集作为训练集,余下的那个子集做测试集。这样可以获得k组“训练/测试集”,最终返回的是k个结果的均值。
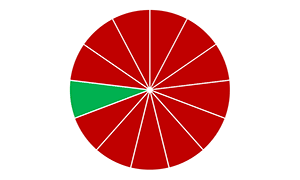
D分为k份,即每一份既可以做训练集也可以做测试集。即可进行k次验证,最后结果取均值。因此又叫【k-折交叉验证法】。
而真正应用时交叉验证法得到的结果是均值的均值,即p个“k个结果的均值”的均值,因此交叉验证法又可以叫做p次k折交叉验证。
k最常取10
优点:准确;缺点:开销大
自助法
对有m个样本的数据集D,按如下方式采样产生数据集D’:每次随机取一个样本拷贝进D’,取m次(有放回取m次)。
按此方法,保证了D’和D的规模一致。但D’虽然也有m个样本,可其中中会出现重复的样本,而D中会存在D’采样没有采到的样本,这些样本就留作测试集。
某样本在m次采样中均不会被采到的概率是:,取极限可得
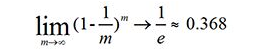
由此可知,理论上有36.8%的样本没有出现在在D’之中。
优点:训练集与数据集规模一致;数据集小、难以有效划分训练集和测试集时效果显著;能产生多个不同的训练集;
缺点:改变了训练集的样本分布,引入估计偏差。
性能度量(难点)
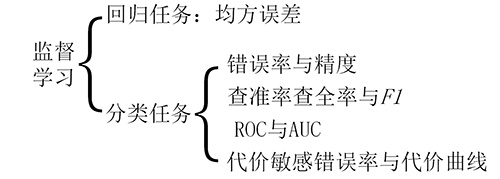
回归任务——均方误差
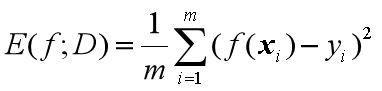
但对于数据分布Ɗ和概率密度p(·),均方误差的计算公式如下:
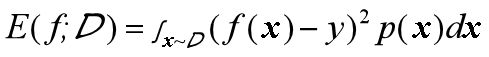
式1可看作离散样本,式2可看作连续样本
均方误差当然是越小越好
分类任务
- 错误率与精度
错误率与精度反应的是分类任务模型判断正确与否的能力。
错误率: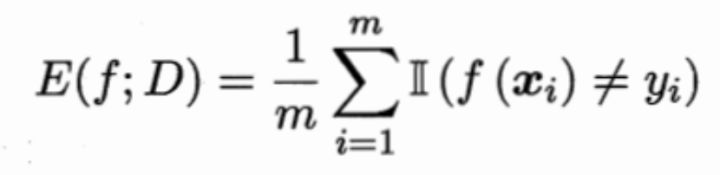
精度: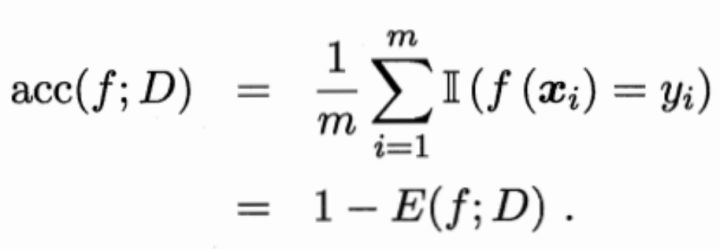
对于一般的数据分布:
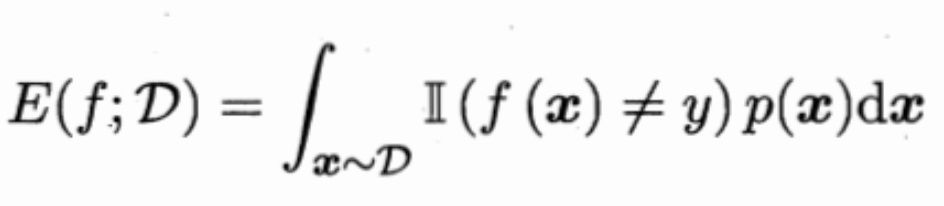
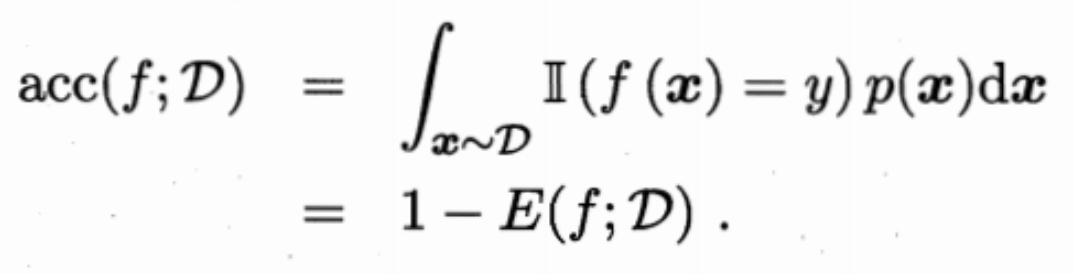
- 查准率、查全率、F1
如果想知道相关比例信息,如推荐的信息中有多少比例是用户真正感兴趣的,或者用户感兴趣的信息中有多少被检索了出来,则需要查准率(precision)与查全率(recall)来进行度量。
在二分类问题中,可将样本分为四类:真正例(TP)、假正例(FP)、假反例(FN)、真反例(TN)。
查准率即检测出的正例占所有正例的比例。即假正例是没有被预测出来的正例。
查准率是检测出的’真正正例’占所有’预测为正例’的样本的比例。
当我们追求准确率时,即希望查准率高,当我们希望把所有正例都选择出来时,希望查全率高。
一般来说,查准率高时,查全率偏低;查全率高时,查准率偏低。通常只在一些简单任务中,查准率和查全率都偏高。
P-R图:判断查准率和查全率的性能
P-R图,即以查全率做横轴,查准率做纵轴的平面示意图,通过P-R曲线,来综合判断模型的性能。
同一个模型,在同一个正例判断标准下,得到的查准率和查全率只有一个,也就是说,在图中,只有一个点,而不是一条曲线。
那么要得到一条曲线,就需要不同的正例判断标准
具体的方式是,先对结果进行排序,前面的是最可能的,后面的是最不可能的正例样本。逐个把每一个样本加入正例,计算当前状况下的查准率和查全率
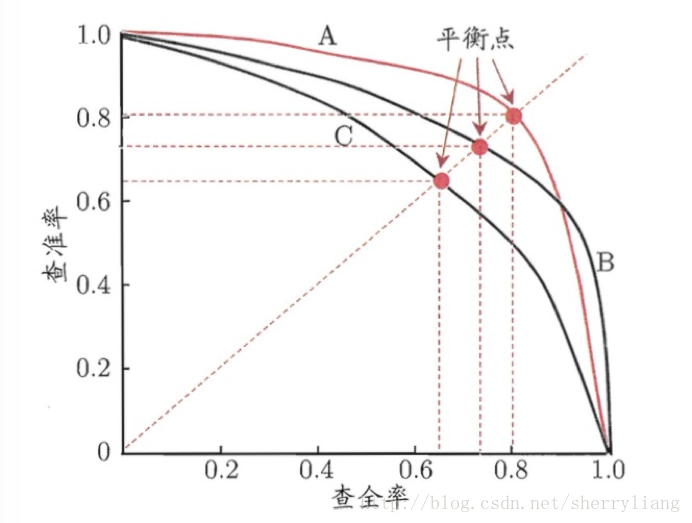
当曲线没有交叉的时候:外侧曲线的学习器性能优于内侧;
当曲线有交叉的时候:
第一种方法是比较曲线下面积,但值不太容易估算;
第二种方法是比较两条曲线的平衡点,平衡点是“查准率=查全率”时的取值,在图中表示为曲线和对角线的交点。平衡点在外侧的曲线的学习器性能优于内侧。
第三种方法是F1度量和Fβ度量。F1是基于查准率与查全率的调和平均定义的,Fβ则是加权调和平均。
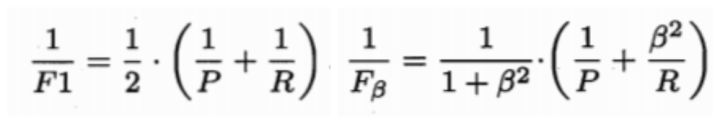

但在不同的应用中,对查准率和查全率的重视程度不同,需要根据其重要性,进行加权处理,故而有了Fβ度量。β是查全率对查准率的相对重要性。
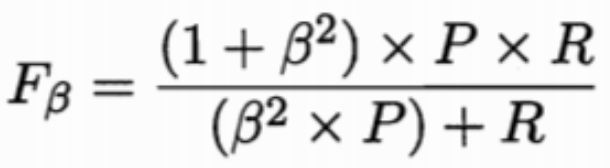
- ROC与AUC
通过设定不同的阈值划分正反例,如可能性为50%以上就认为是正例,或60%,70%….进而得到某个特定阈值下的真正例率和假正例率。
ROC与PR图有相似之处,即都是将样本排序进行划分后计算,不同的是计算的度量值不同,同时PR是逐个划分,ROC是对阈值进行变化。
真正例率(TPR):所有正例中被预测出来的正例占得比例(等于查全率)
假正例率(FPR):没有被预测出的反例(即预测错误的正例)占全部反例的比例
注意上图和之前那张图的横竖轴是相反的
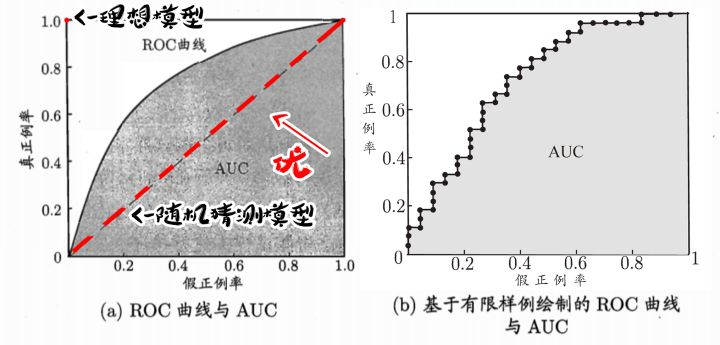
理想模型是真正例率为100%,假正例率为0%的一点。随机猜测模型则是真正例率与假正例率持平的直线。
两个学习器进行比较时,一个被另一个包住则后者性能好,如果发生了交叉,通常比较面积,即AUC
可以认为是将图b分解为好多个小矩形。计算矩形面积和。当时AUC为0,当时,,乘0.5还是的值,即矩形的高。产生这种巧合的原因,是ROC的绘制过程决定的。
有限个点的ROC绘制:
先将分类阈值设为最大,即把所有样例设为反例,此时真正例率和假正例率都为0(TP=0,FP=0)。在(0,0)处标一个点。然后分类阈值一次设为每个样例的预测值,即依次将每个样例划分为正例(这就与PR曲线类似了,只是横纵坐标不同),设前一个点坐标为(x,y),若为真正例,对应标记点为(TP上升,TPR上升,y增加,FP 不变,FPR不变,x不变),若为反例则坐标为。
所以ROC上坐标都是平行或者垂直的,故可以推出面积公式。
AUC考虑的是样本预测的排序质量。给定个正例和个反例,和分别表示正、反例集合,则排序损失为
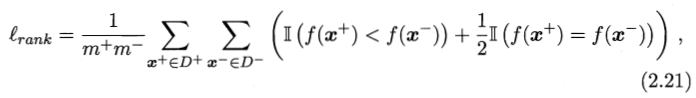
可理解为,若正例的预测值小雨反例,记一个罚分,若相等,记0.5分。
- 代价敏感错误率与代价曲线
非均等代价:通常不同的错误造成的严重后果不同,所以要给不同的代价一定权重
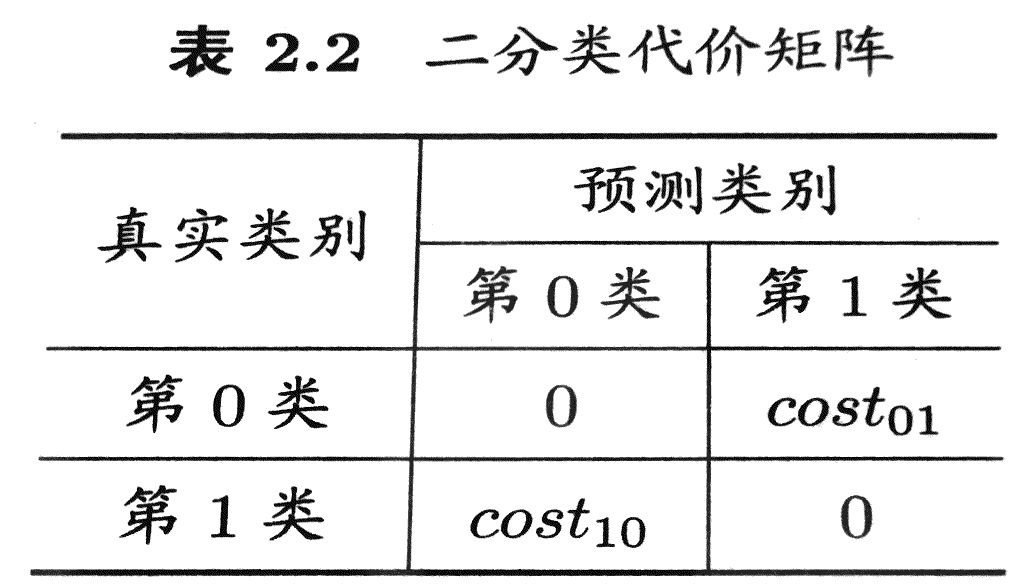
非均等代价的错误率:
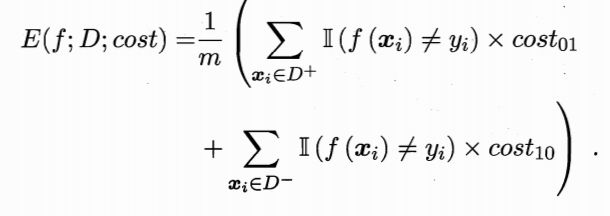
在这样的非均等代价下,ROC曲线不能直接反映出学习器的期望总体代价,而“代价曲线”则可以达到目的。
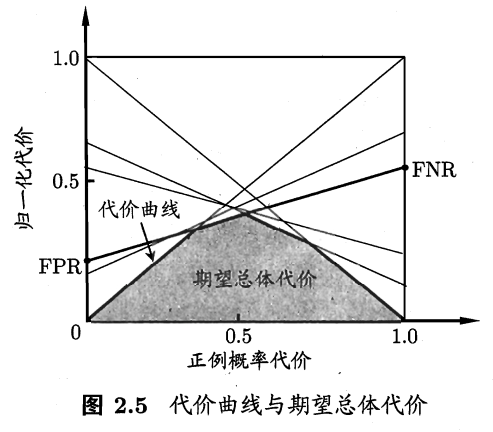
代价曲线的横轴是正例概率代价,纵轴是归一化代价 。
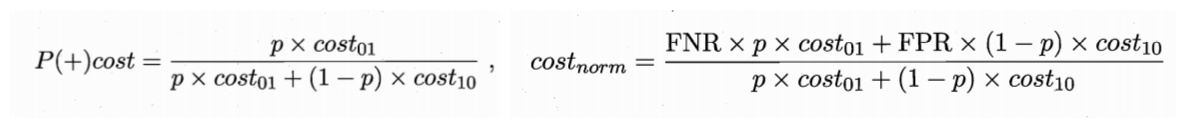
p是样例为正例的概率;FNR是假反例率;FPR是假正例率。
绘制方法:
ROC曲线上取一个点(FPR,TPR);
取相应的(0,FPR)和(1,FNR),连成线段;
取遍ROC曲线上所有点并重复前步骤;
所有线段的下界就是学习器期望总体代价。
实际上就是通过将样例为正例的概率p设为0和1,来作出曲线的所有切线,最后连成曲线。
泛化误差分解
泛化误差=偏差+方差+噪声
预测的期望(所有预测的均值)