SGD与词向量
在每一个窗口中,我们最多只有2m+1个单词,所以会非常稀疏
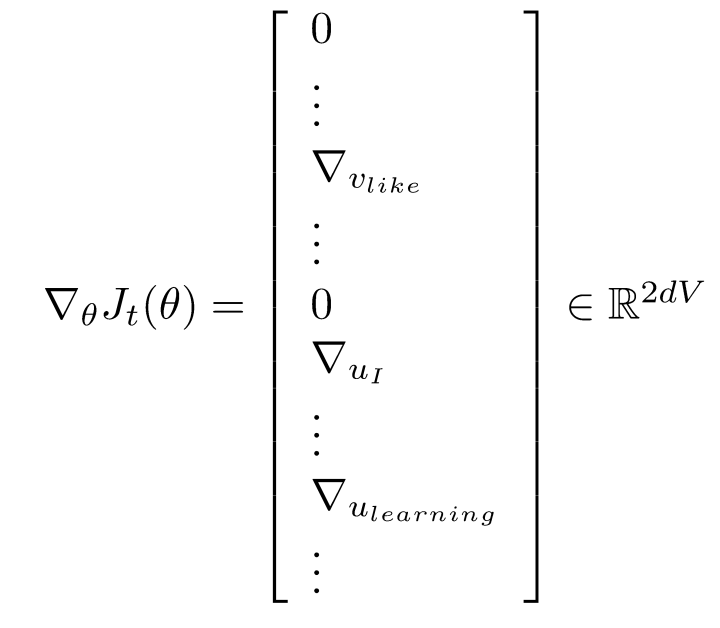
我们实际上只更新了出现在窗口中的那些词的列
所以我们只需要更新词向量矩阵U和V中的少数列,或者为每个词和词向量建立一个hash映射
负采样
词向量矩阵的量级很大,所以下面式子的分母很难计算
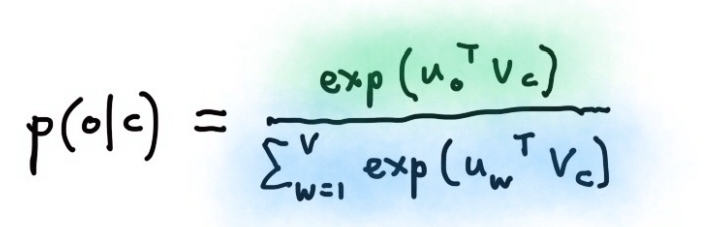
之前我们提到word2vec有两种高效的训练方法:
- Hierarchical softmax
- Negative sampling
而我们第一节课采用了更简单的naive softmax
而negative sampling简化计算的步骤是:具体做法是,对每个正例(中央词语及上下文中的一个词语)采样几个负例(中央词语和其他随机词语),训练binary logistic regression(也就是二分类器)。
negative sampling和skip-gram
目标函数:
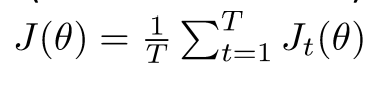
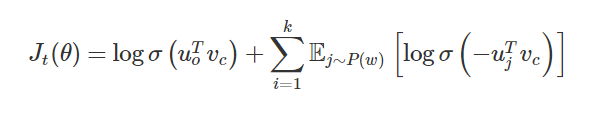
这里t是某个窗口,k是采样个数
是sigmoid函数
所以上式可以化为:
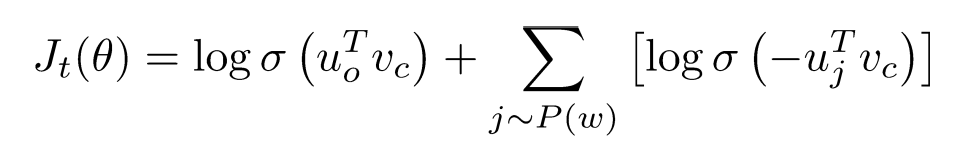
- 需要做的是最大化第一项(真实出现在中心词上下文的词),最小化第二项(随机选取的词)
- P(w)是一个unigram分布
word2vec通过把相似词语放到同一个地方来增大目标函数(内积大嘛)

其他方法
word2vec将窗口视作训练单位,每个窗口或者几个窗口都要进行一次参数更新。要知道,很多词串出现的频次是很高的。能不能遍历一遍语料,迅速得到结果呢?
早在word2vec之前,就已经出现了很多得到词向量的方法,这些方法是基于统计共现矩阵的方法。如果在窗口级别上统计词性和语义共现,可以得到相似的词。如果在文档级别上统计,则会得到相似的文档(潜在语义分析LSA)。
基于窗口的共现矩阵X
我们先规定一个固定大小的窗口,然后统计每个词出现在窗口中次数,这个计数是针对整个语料集做的。可能说得有点含糊,咱们一起来看个例子,假定我们有如下的3个句子,同时我们的窗口大小设定为1(把原始的句子分拆成一个一个的词):
- I enjoy flying.
- I like NLP.
- I like deep learning.
由此产生的计数矩阵如下:
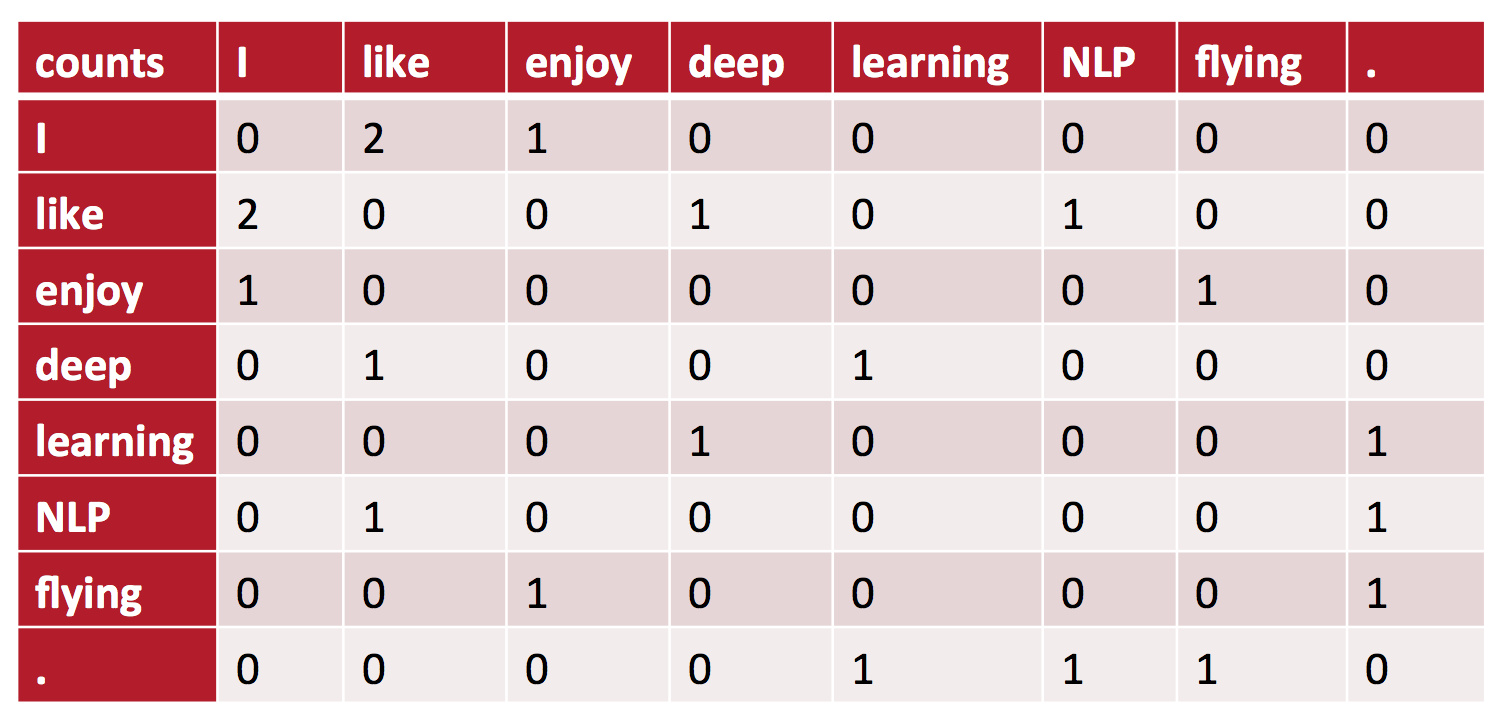
根据这个矩阵,的确可以得到简单的共现向量。但是它存在非常多的局限性:
当出现新词的时候,以前的旧向量连维度都得改变
高纬度(词表大小)
高稀疏性
通过降维减少计算量,用25到1000的低维稠密向量来储存重要信息。
通过SVD进行降维
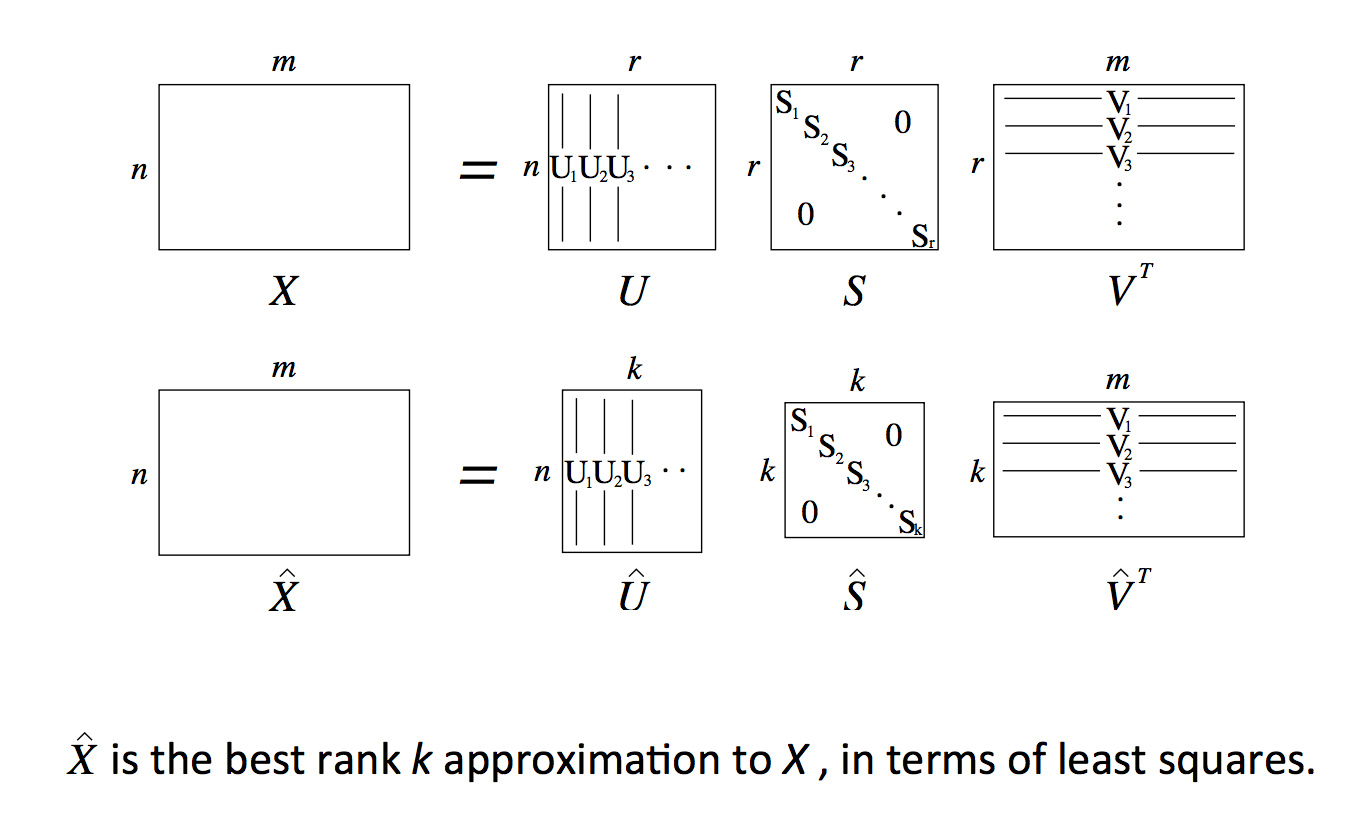
r维降到d维,取奇异值最大的两列作为二维坐标可视化:
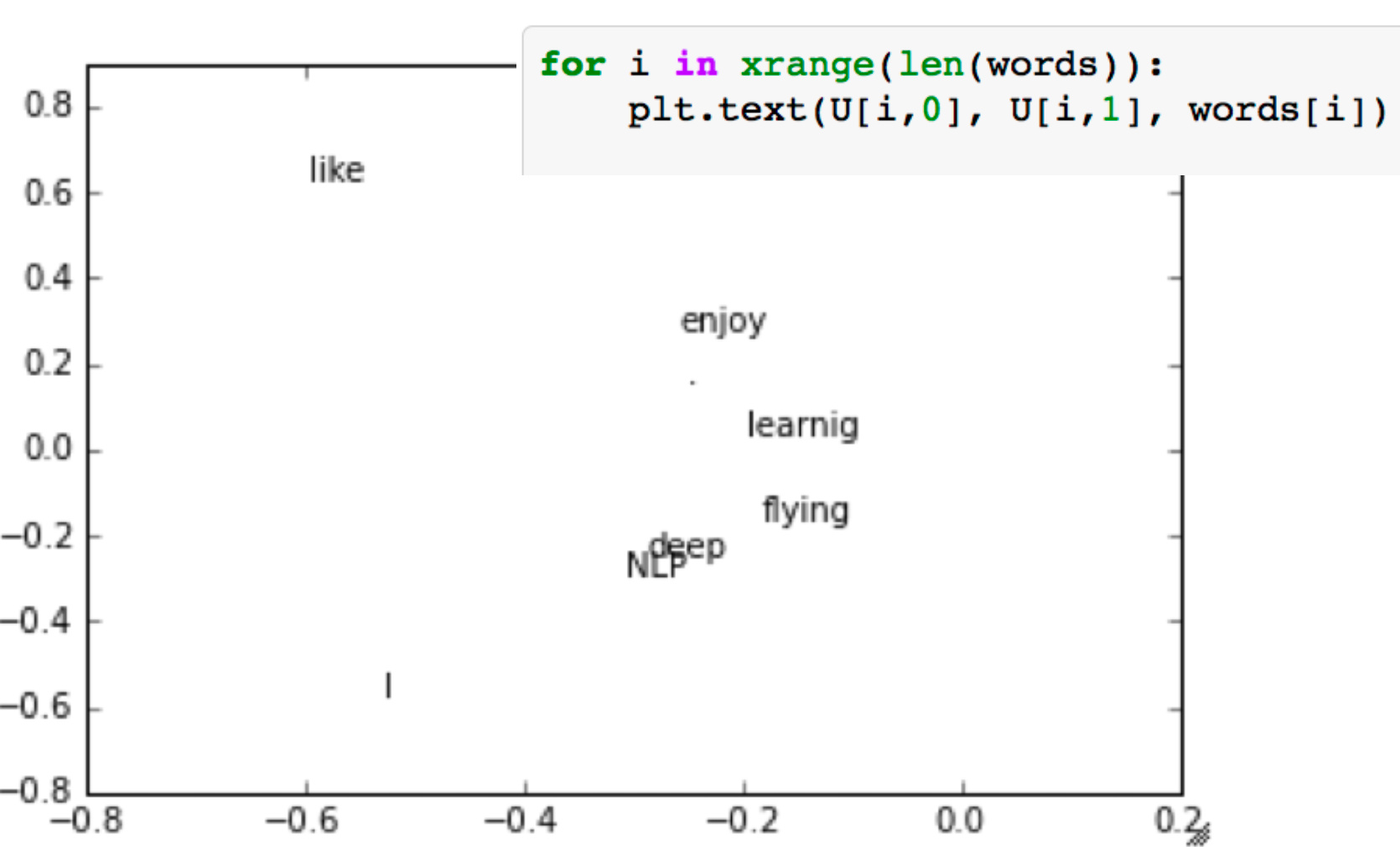
改进:
限制高频词(a,the,he,has…)的频次(如最大为100,超过就不再计数),或者干脆停用词
根据与中央词的距离衰减词频权重
用皮尔逊相关系数代替词频
效果还不错:


SVD的问题
- 计算复杂度高,对m*n的矩阵 O()
- 不方便处理新词和新文档
- 与其他DL模型训练套路不同
基于统计的词向量模型vs基于预测的词向量模型(Count based vs direct prediction)
前者以基于SVD分解技术的LSA模型为代表,通过构建一个共现矩阵得到隐层的语义向量
优点:充分利用了全局的统计信息。
缺点:然而这类模型得到的语义向量往往很难把握词与词之间的线性关系(例如著名的King、Queen、Man、Woman等式)。
后者则以基于神经网络的Skip-gram模型为代表,通过预测一个词出现在上下文里的概率得到embedding词向量。
优点:其得到的词向量能够较好地把握词与词之间的线性关系,因此在很多任务上的表现都要略优于SVD模型。
缺点:这类模型的缺陷在于其对统计信息的利用不充分,训练时间与语料大小息息相关。
综合两者优势:GloVe
这种模型的目标函数是:
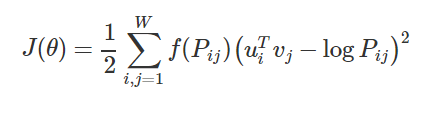
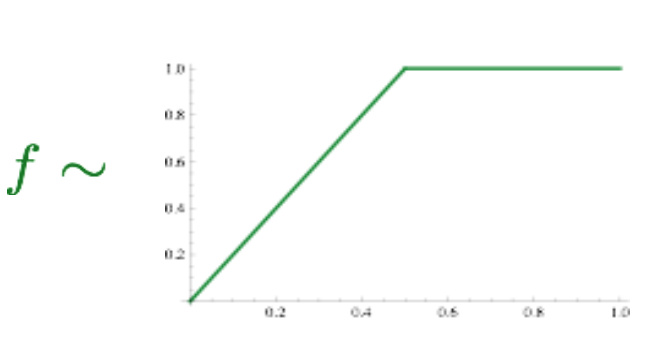
这里的Pij是两个词共现的频次,f是一个max函数,用于降低高频词对模型的干扰:
优点是训练快,可以拓展到大规模语料,也适用于小规模语料和小向量。
这里面有两个向量u和v,它们都捕捉了共现信息
试验证明,最佳方案是简单地加起来:
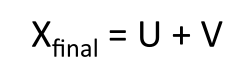
相对于word2vec只关注窗口内的共现,GloVe这个命名也说明这是全局的
模型的评估:
通常有两种方式:Intrinsic和Extrinsic
Intrinsic:
- 关注模型在一个特定子任务上的表现
- 快速便捷
- 有助于更好地理解模型内在的性质
- 可能实际应用时效果不好
Extrinsic:
- 关注在一个具体任务上的表现,如机器翻译或情感分析
- 通常比较耗时
- 比Intrinsic评估更具有参考意义
Intrinsic评估
对于词向量模型,一个常用的Intrinsic评估是向量类比(word vector analogies)。它评估了一组词向量在语义和句法上表现出来的线性关系。具体来说,给定一组词(a, b, c, d),我们要验证的是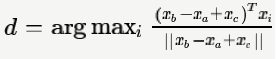 ,即d是与向量的cosine距离最近的词。
,即d是与向量的cosine距离最近的词。

Mikolov在他的word2vec开源工具包里也提供了用于word
analogy评估的数据集。例如国家与首都的类比数据,时态或是比较级的类比数据。
借助于Intrinsic评估,我们也可以方便快捷地对模型的超参数(Hyperparameters)进行选择。例如向量的维度,context window的大小,甚至是模型的选择。
一些有趣的类比:
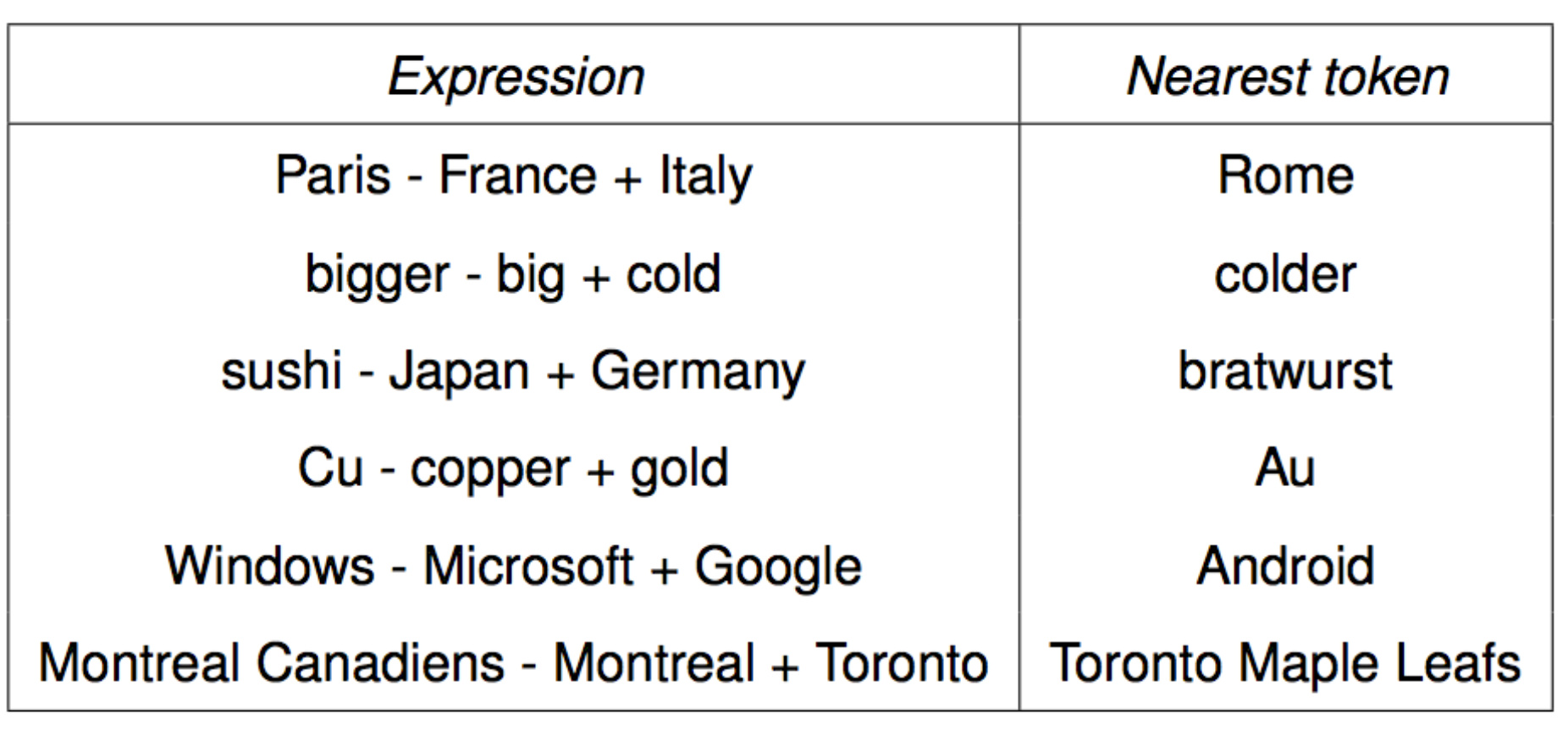
训练结果
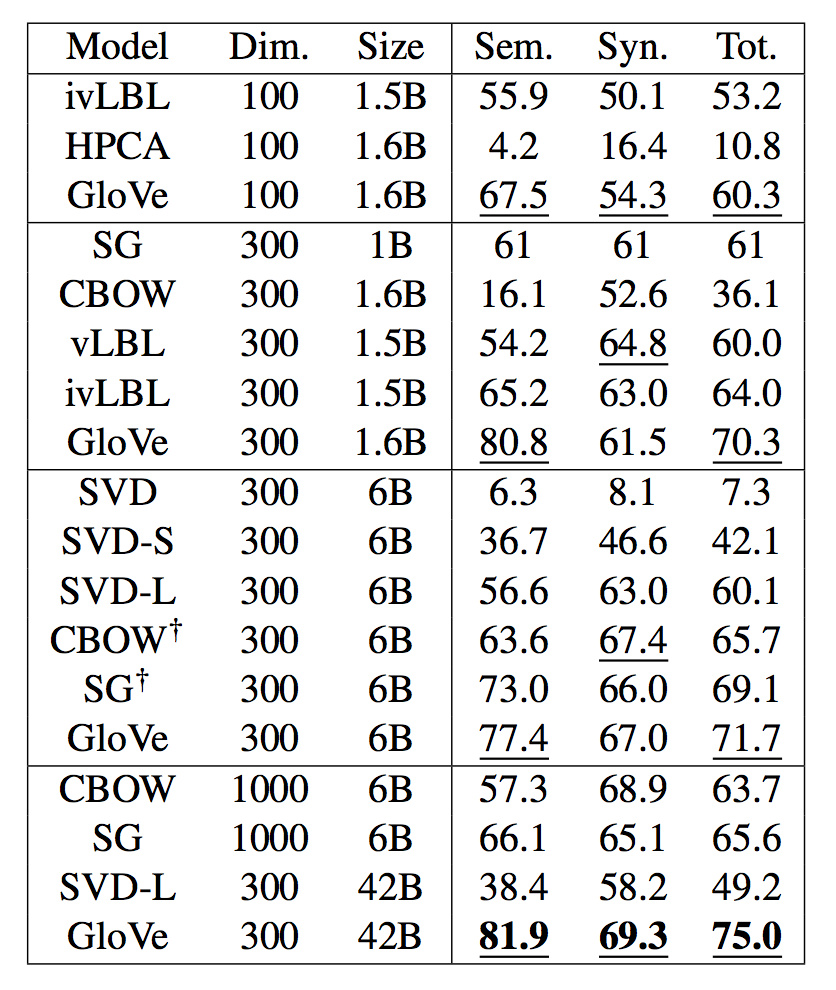
Glove效果是最好的。
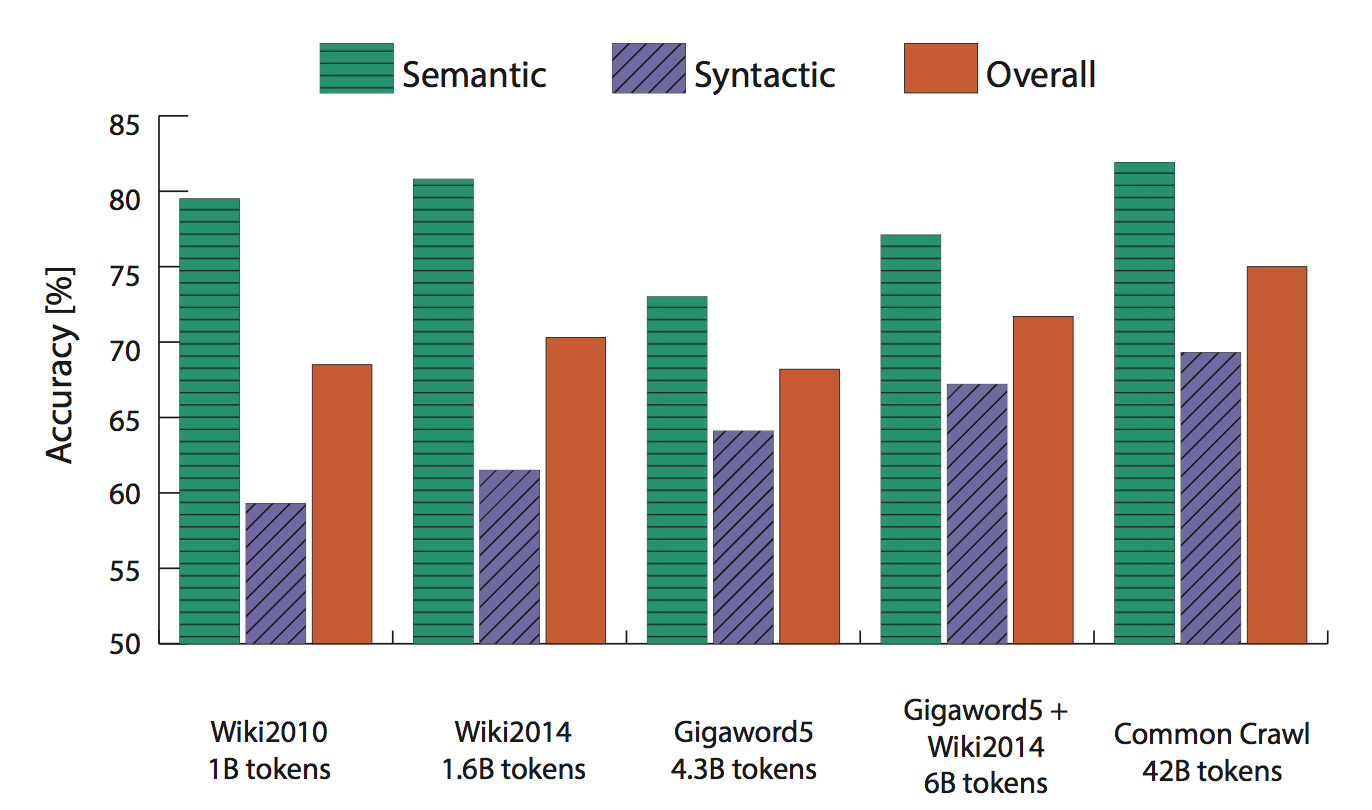
另外高维度数据效果不一定好,而数据量越多效果越好
调参
主要是几个参数:窗口是否对称(还是只考虑前面的单词),向量维度,窗口大小
300维,窗口大小为8的对称窗口效果较好。
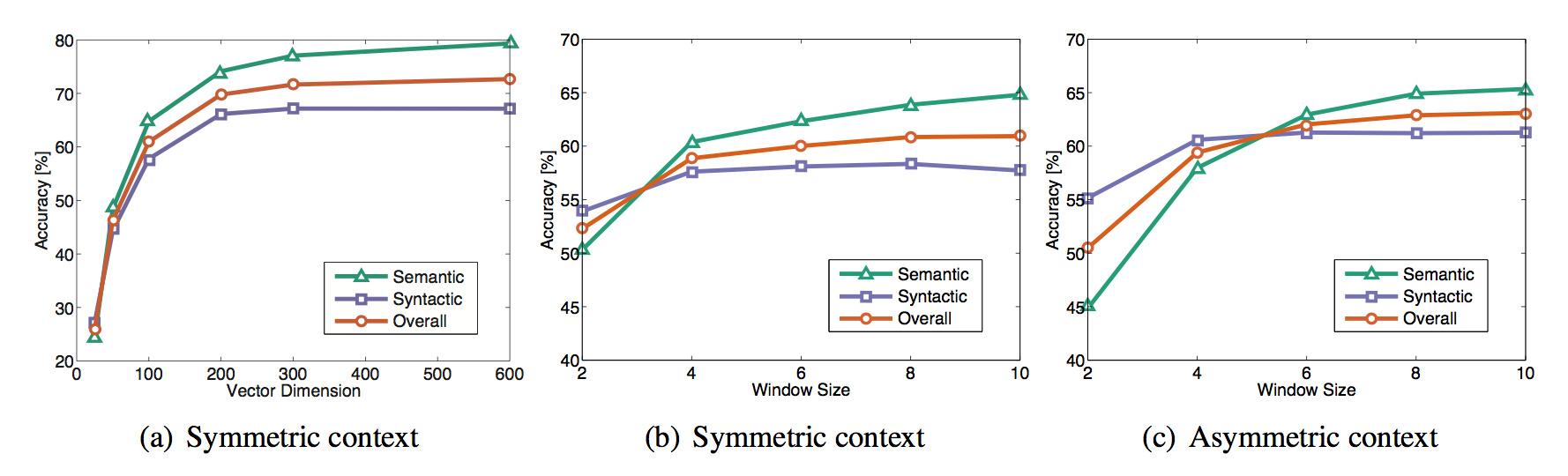
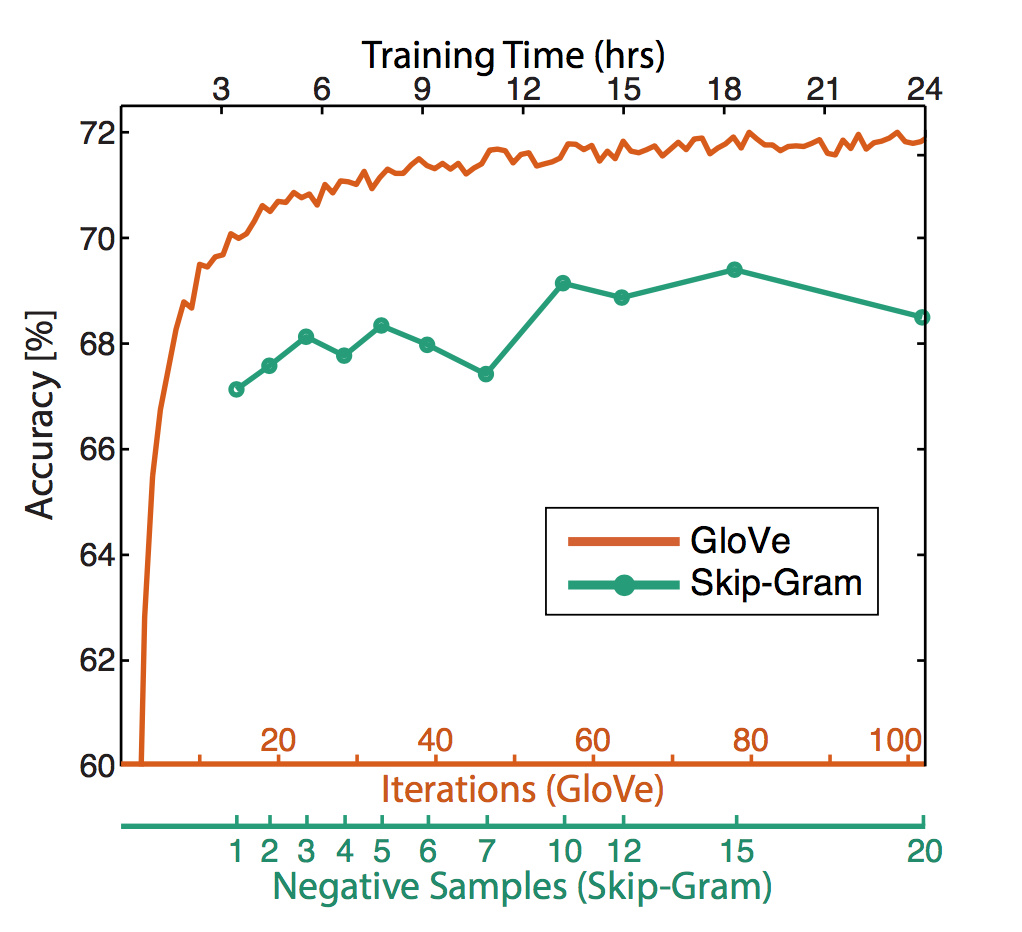
迭代次数越多,效果越稳定
维基百科语料比新闻语料效果好,主要是因为一些词在新闻中很少出现
Extrinsic评估
值得注意的是,即使一些模型在人为设定的Intrinsic任务上表现较弱,并不能说明它们在具体的真实任务中毫无优势。Intrinsic评估的主要作用是对模型的超参数进行初步的调整和选择(这种模型选择在Extrinsic任务上往往极为耗时)。而评估模型的优劣还是要看它在Extrinsic任务上的表现。
对于词向量模型,常见的Extrinsic任务是对词向量进行分类。例如命名实体识别(NER)和情感分析。理论上,如果我们习得的词向量足够精确,那么语义或句法上相近的词必然分布在同一片向量空间。这就使得基于词向量的分类更加准确。
采用Extrinsic评估时我们用的还是softmax函数。具体上一篇已经写过了。
word2vec适用范围
对单词分类比较适合,情感分析就不太适合,
歧义消解
中心思想:通过上下文聚类,对不同词义分门别类进行训练

相同颜色的是同一个单词的不同义项。